
Cross Language Computing for Indic Languages

2
Internet penetration
in India
Growth in Internet users
Y-o-Y (based on last 1 year)
Literates in India Multilingual Users
Internet & Multilingual Statistics
25% 13.33% 250 Mn. 560 Mn.
Sources: TRAI Counterpoint Research Government of India Census 2011
Needs of mobile first local language users and English language users are the same
Contacts Messaging Search Browsing
3
Fundamental Usage
Most software ignore language specific character sets Encoding guidelines are not followed. Confusions grow
Encoding Display
Design considerations in display stack
Ambiguities
Input methods
Native
English
4
Challenges of Indic Computing
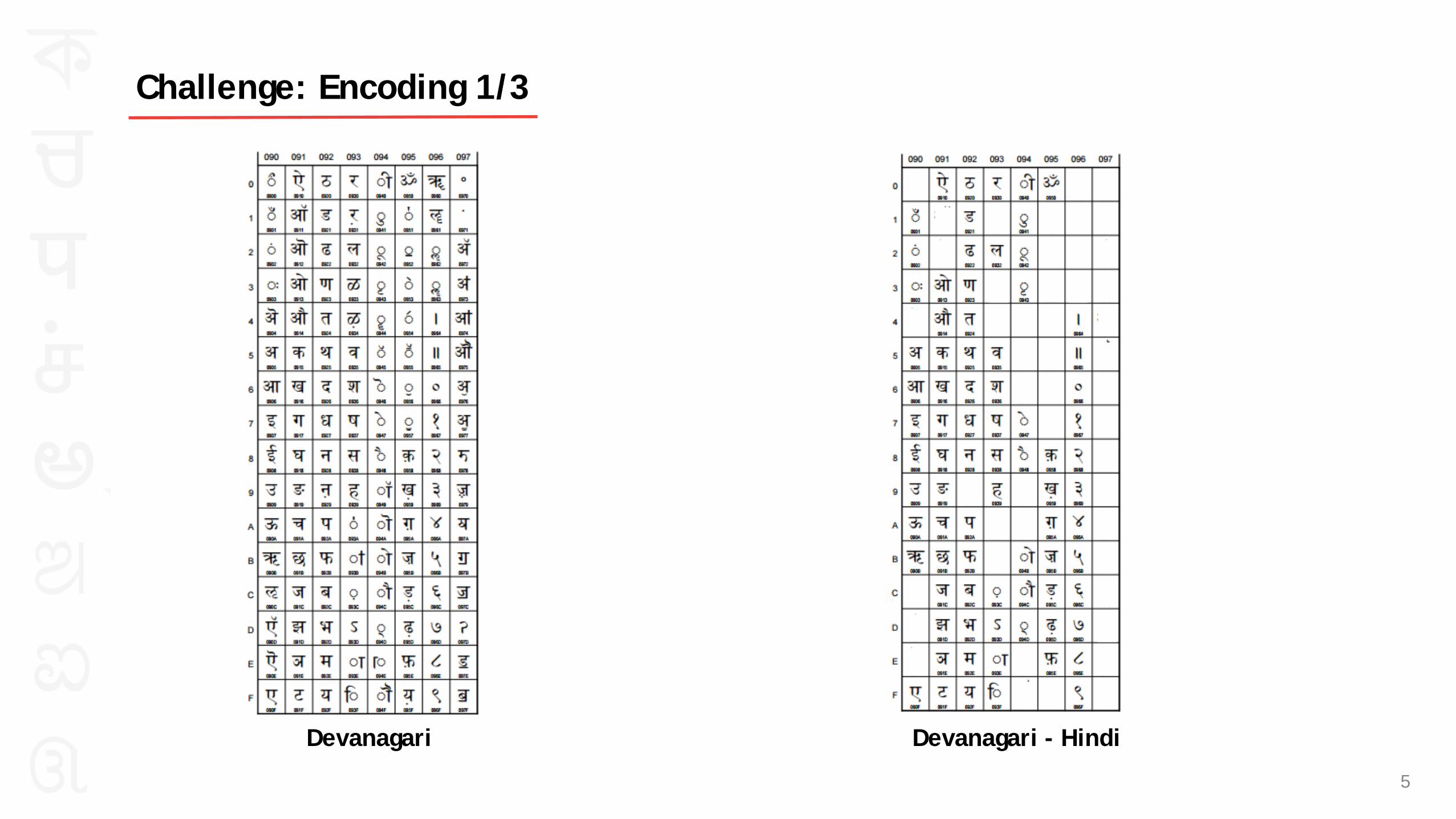
Devanagari Devanagari - Hindi
5
Challenge: Encoding 1/3
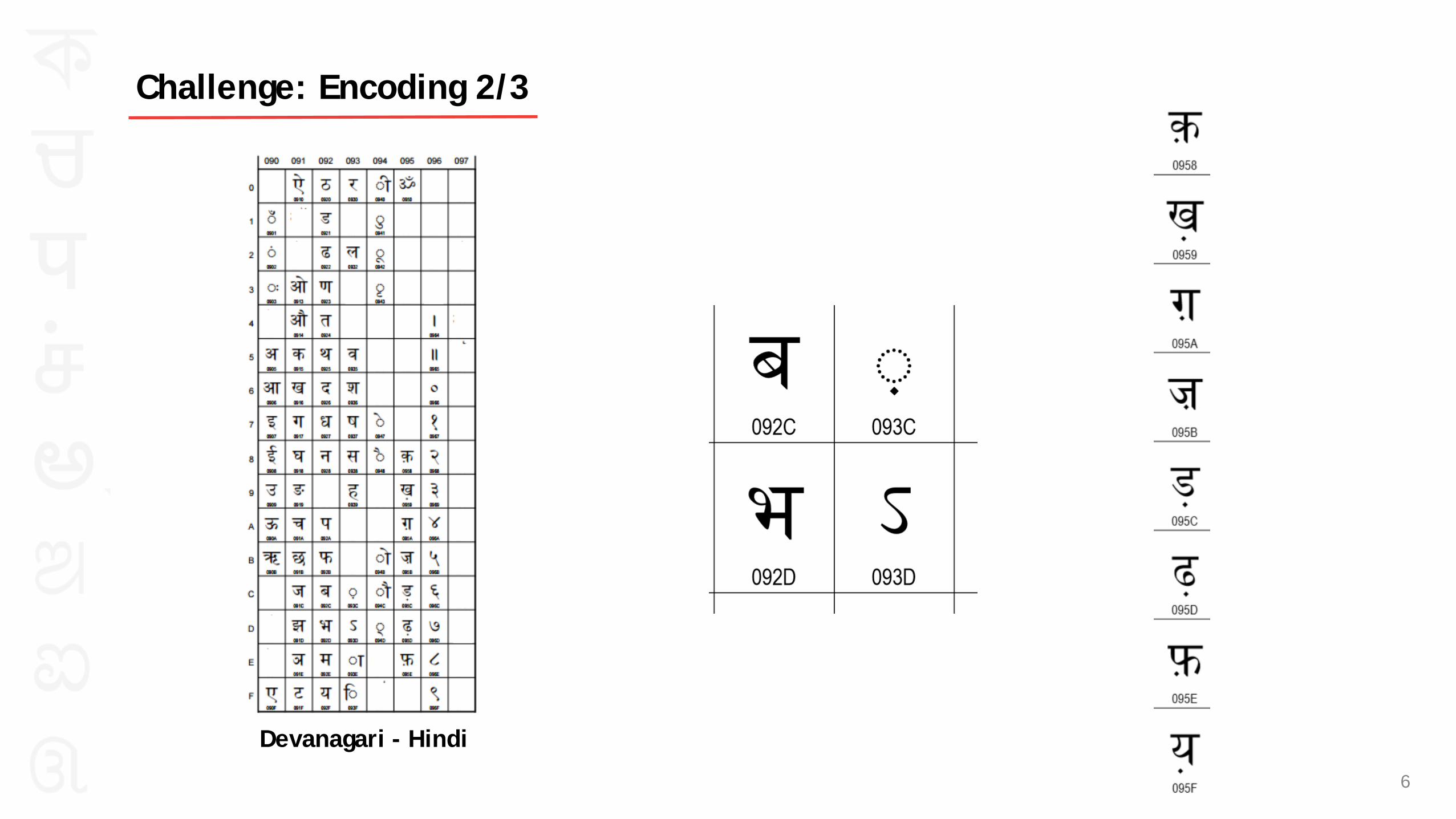
Devanagari - Hindi
6
Challenge: Encoding 2/3
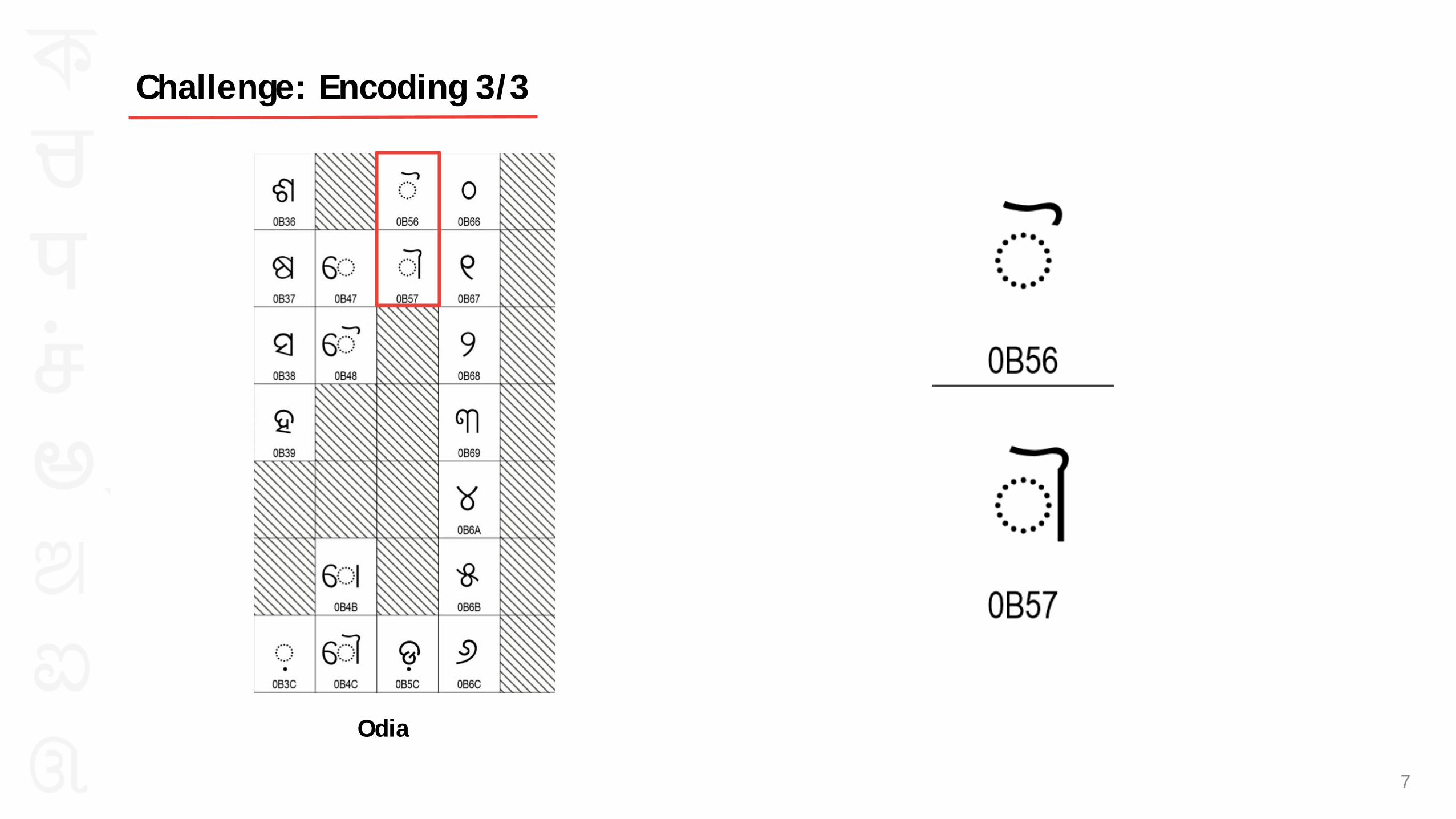
Odia
7
Challenge: Encoding 3/3

Hindi
8
Challenge: Display 1/2
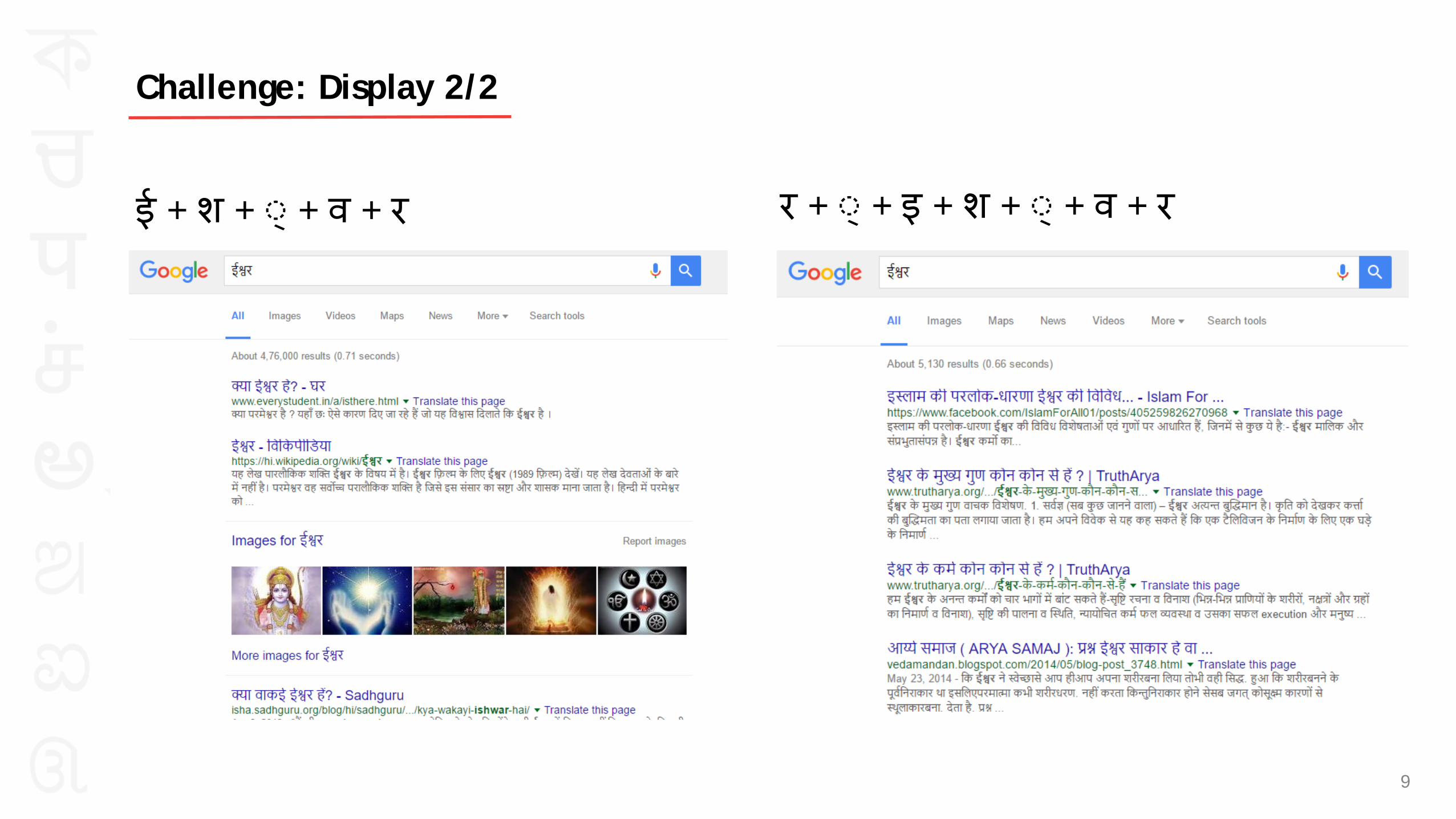
ई + श + ◌् + व + र र + ◌् + इ + श + ◌् + व + र
9
Challenge: Display 2/2
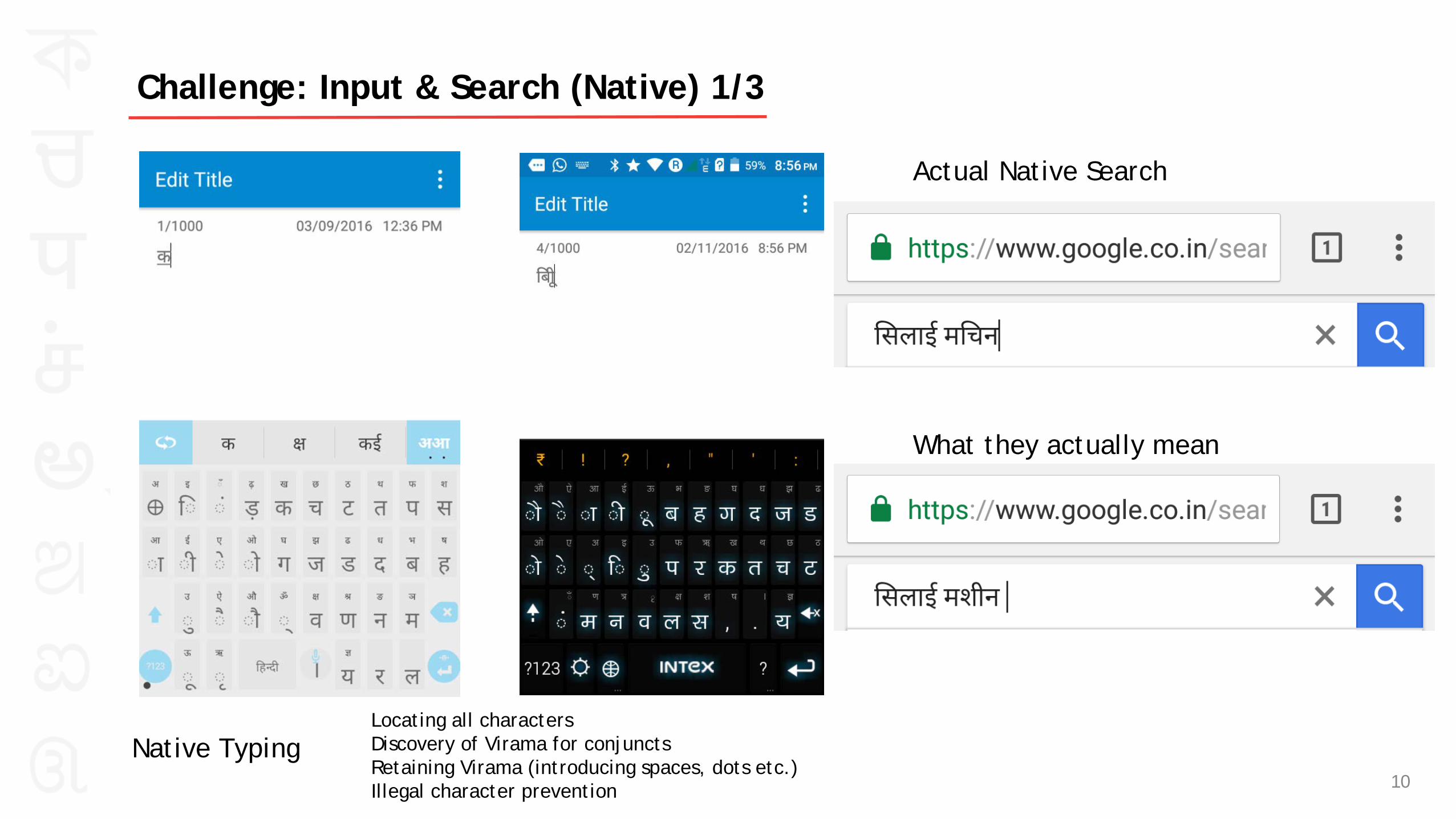
Native Typing
Actual Native Search
What they actually mean
Locating all characters Discovery of Virama for conjuncts Retaining Virama (introducing spaces, dots etc.) Illegal character prevention 10
Challenge: Input & Search (Native) 1/3
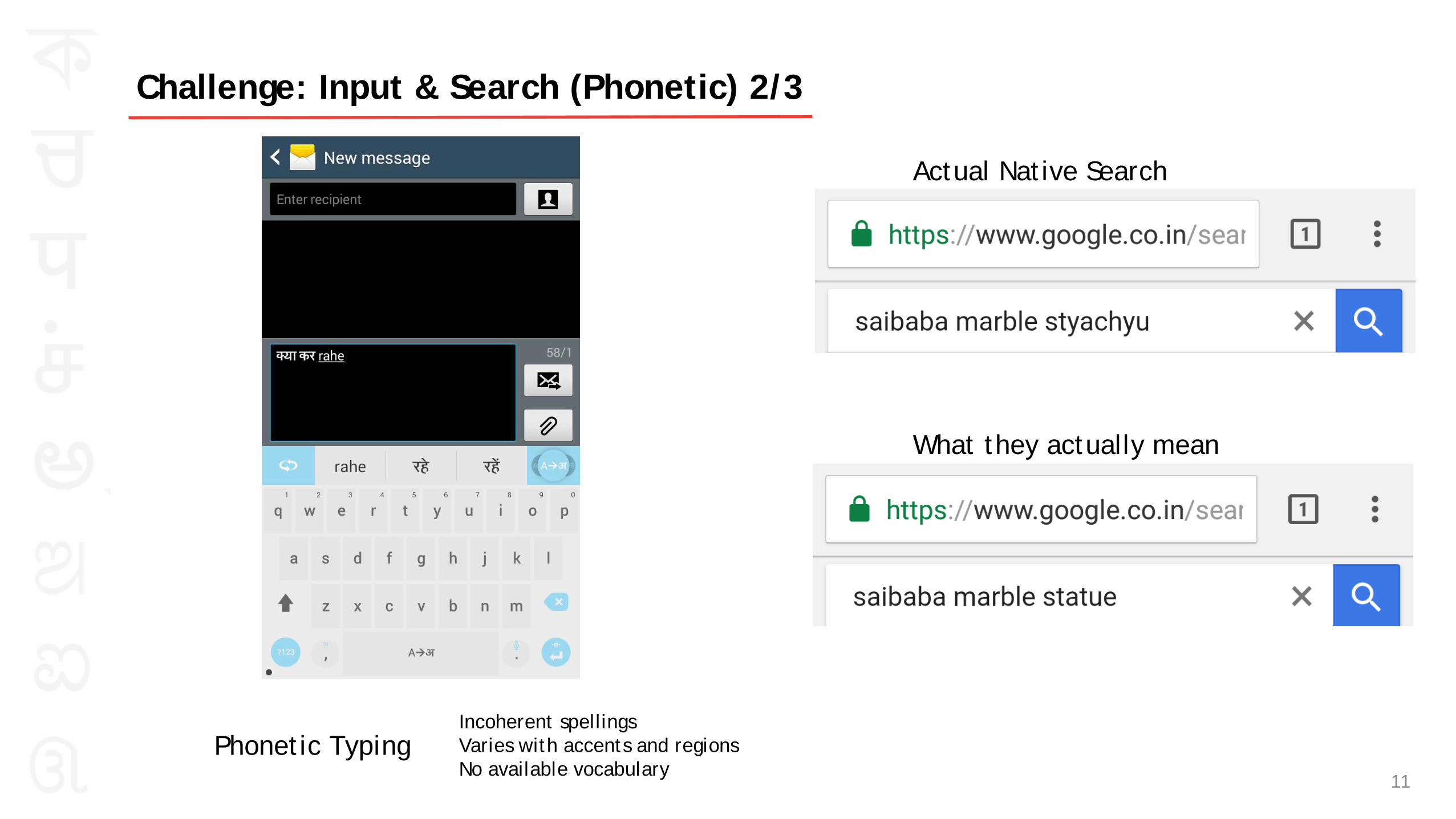
Phonetic Typing 11
Challenge: Input & Search (Phonetic) 2/3
Incoherent spellings Varies with accents and regions No available vocabulary
Actual Native Search
What they actually mean
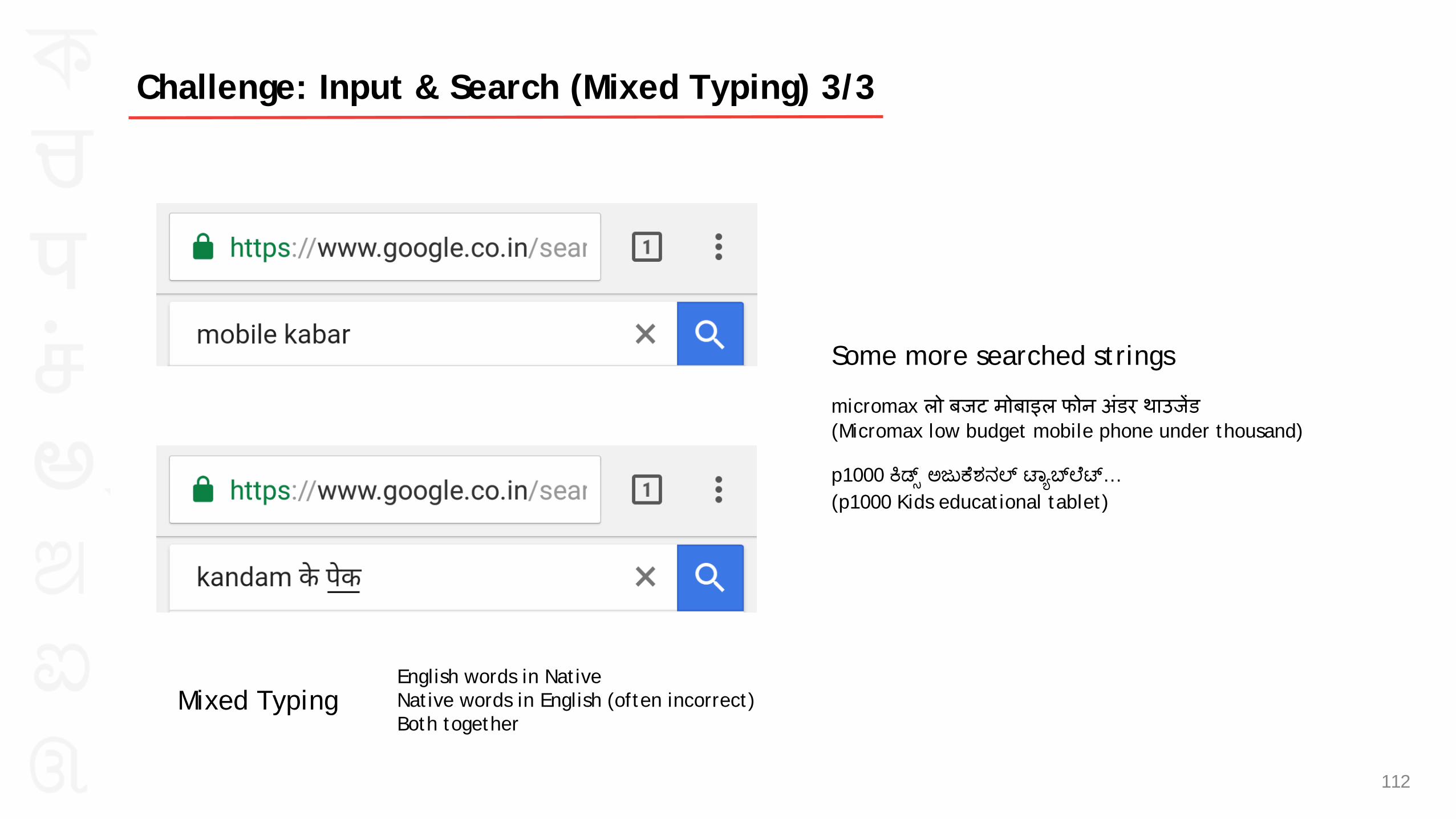
Mixed Typing
Some more searched strings micromax लो बजट मोबाइल फोन अंडर थाउज�ड (Micromax low budget mobile phone under thousand)
p1000 �ಡ್ ಅಜು�ೆಶನಲ �ಾ�ಬ ್ೆೆ… (p1000 Kids educational tablet)
112
Challenge: Input & Search (Mixed Typing) 3/3
English words in Native Native words in English (often incorrect) Both together

English orthographic based methods do not work
Indic languages are phonetic but accents influence widely Sandhi (Agglutination) in some families are deep and complex
Basic NLP like Spell Checking and word segmentations unaddressed
Input methods
Encoding Display
Unsolved
Solved by Reverie
Additional Challenges
Computing Challenges
13

Syntactic Stemming, Lemmatisation, PoS tagging, NER etc. available from various academia but poor
Google’s SyntaxNet released PoS tagging for Hindi and Tamil
Semantic Synonomy, Polysemy, and Word sense disambiguation - Needed
IndoWordNet – Poor and unusable
14
Tools

Language Models Robust n-grams and neural models can be built with standard algorithms and Open source libraries Large corpus data needed to build any model
Challenge: Less than 0.1 % data in the internet in Indian languages Approach: Help create a lot of local language content which will bypass the challenges mentioned: encoding, display
Typing Native and Phonetic Typing Accurate Transliteration for typing (greater than 80%) Spell check, Auto correct and Predict Handwriting and Speech
Discovery and Presentation Intent extraction and search Automated machine translation
15
Solutions

Indian language users today equal English users of 10 years ago in number but growing much faster
English content in the internet was created by users in the past years
All native language content will also get created likewise
The only solution needed is frictionless creation (typing) tool
16
Way Forward : Parallels of English

Divide and Rule - Domain specific vocabularies
- Emphasis on context determination tools
- Use hybrid models
17
How Reverie does it
Translation benchmarks: From a data set of 1000 sentences:
18
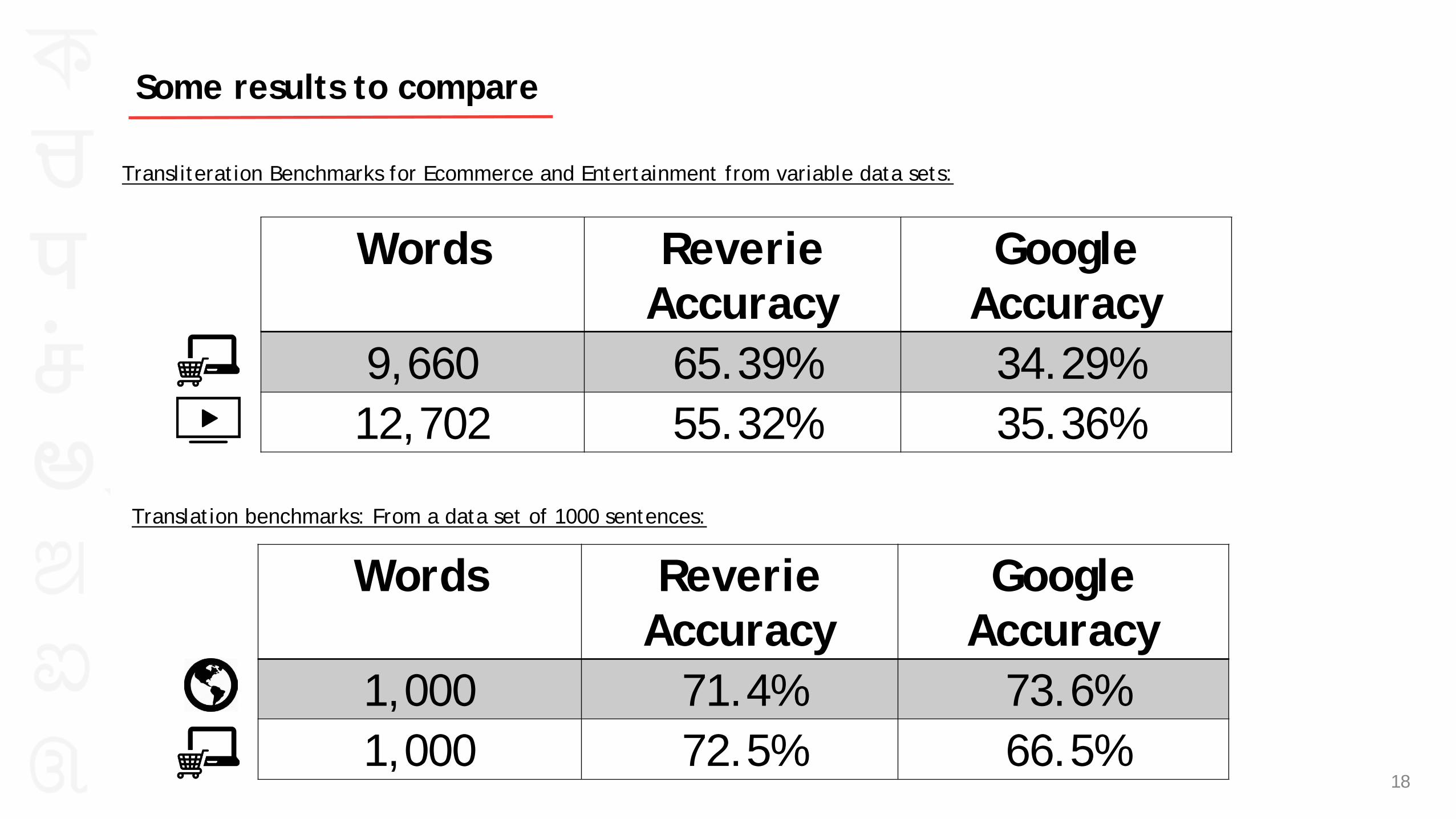
Some results to compare
Transliteration Benchmarks for Ecommerce and Entertainment from variable data sets:
Words Reverie Accuracy
Google Accuracy
9,660 65.39% 34.29% 12,702 55.32% 35.36%
Words Reverie Accuracy
Google Accuracy
1,000 71.4% 73.6% 1,000 72.5% 66.5%
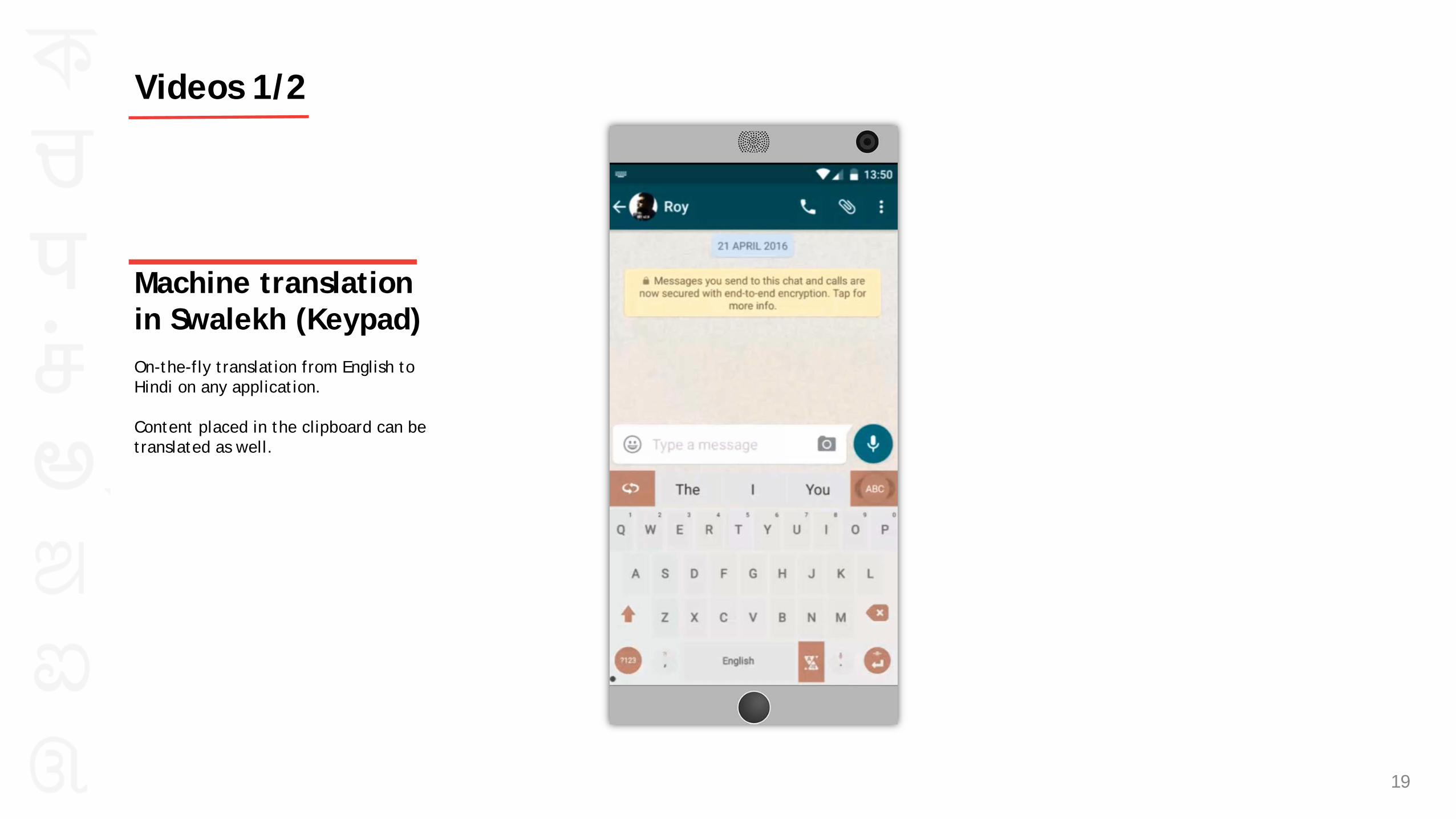
Machine translation in Swalekh (Keypad) On-the-fly translation from English to Hindi on any application. Content placed in the clipboard can be translated as well.
19
Videos 1/2

Phone Book View contacts in any language. Search cross lingual irrespective of input in any language.
20
Videos 2/2

20
Thank you धन्वाा ধনয্বা આભાર நன்ற ధనయ్�ా��ల







