vernoにおける 主記憶検索言語の設計と実装hara/thesis/all/602p044.pdf ·...
TRANSCRIPT

2003年度 修士論文
WWW全文検索システムVernoにおける
主記憶検索言語の設計と実装
提出日: 2003年 2月 5日指導: 上田和紀 教授
早稲田大学院理工学研究科 情報科学専攻
永澤 大介学籍番号:602P044–4

目 次
第 1章 研究の背景と目的 1
1.1 研究の背景 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.1.1 全文検索システムVerno . . . . . . . . . . . . . . . . . . . 1
1.1.2 Vernoの検索言語が抱えていた課題 . . . . . . . . . . . . . 1
1.2 研究の目的 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.3 本論文の構成 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
第 2章 関連研究 4
2.1 プログラミング言語 Scheme . . . . . . . . . . . . . . . . . . . . . 4
2.1.1 Scheme処理系 SCM . . . . . . . . . . . . . . . . . . . . . 4
2.1.2 SXML . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.1.3 SXPath . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.2 情報検索システム . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
第 3章 主記憶検索言語の設計 8
3.1 Vernoにおける検索言語 . . . . . . . . . . . . . . . . . . . . . . . 8
3.1.1 inetdからの起動 . . . . . . . . . . . . . . . . . . . . . . . 10
3.2 主記憶検索言語の設計 . . . . . . . . . . . . . . . . . . . . . . . . 11
3.2.1 処理の流れ . . . . . . . . . . . . . . . . . . . . . . . . . . 11
3.2.2 共有メモリ . . . . . . . . . . . . . . . . . . . . . . . . . . 11
3.2.3 扱うデータ . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3.3 本研究の対象データ . . . . . . . . . . . . . . . . . . . . . . . . . 15
3.4 用いたハードウェアとオペレーティングシステム . . . . . . . . . 15
第 4章 主記憶検索言語の実装 17
4.1 ファイル変換 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
4.1.1 larbin2xml . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
4.1.2 xml2verno . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
4.1.3 xml2sxml . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
4.1.4 1-Gramデータ . . . . . . . . . . . . . . . . . . . . . . . . 19
4.2 共有メモリセグメントへの展開 . . . . . . . . . . . . . . . . . . . 20
4.2.1 Schemeのデータ型とその内部表現 . . . . . . . . . . . . . 20
1

4.2.2 SXMLデータ . . . . . . . . . . . . . . . . . . . . . . . . . 21
4.2.3 その他のデータ . . . . . . . . . . . . . . . . . . . . . . . . 22
4.2.4 GarbageCollectionの回避 . . . . . . . . . . . . . . . . . . 23
4.3 SCM上からの利用 . . . . . . . . . . . . . . . . . . . . . . . . . . 25
4.3.1 見えない . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
4.3.2 shm-copy . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
4.3.3 equal? eq?関数 . . . . . . . . . . . . . . . . . . . . . . . . 27
4.3.4 実装した Scheme関数 . . . . . . . . . . . . . . . . . . . . . 28
第 5章 評価 30
5.1 データの主記憶への展開 . . . . . . . . . . . . . . . . . . . . . . . 30
5.2 文字列検索の使用例 . . . . . . . . . . . . . . . . . . . . . . . . . 31
5.3 SXMLデータの使用例 . . . . . . . . . . . . . . . . . . . . . . . . 32
5.4 破壊的代入 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
5.5 応用例 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
5.5.1 画像の一覧を作成する . . . . . . . . . . . . . . . . . . . . 34
5.5.2 表を加工する . . . . . . . . . . . . . . . . . . . . . . . . . 35
第 6章 考察 36
6.1 有用性 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
6.2 処理速度 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
6.3 主記憶の使用量に関して . . . . . . . . . . . . . . . . . . . . . . . 39
第 7章 まとめと今後の課題 41
7.1 まとめ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
7.2 今後の課題 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
参考文献 43
付 録A 付録 44
A.1 sample1.scm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
A.2 sample2.scm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
2

概 要
Verno1は「プログラマブルな検索エンジン」をコンセプトとする、WWW全文検索システムである。Vernoは、データベースを利用するための検索言語にプログラミング言語 Schemeを用いており、ユーザーは複雑な検索を対話的に行う事が出来る。
Vernoにおける従来の検索言語は、Schemeならではのデータがシステムで用意されていない、データを得るための関数がわかりにくい、処理系がサーバ化が考慮されていない、など、様々な問題を抱えていた。これらの問題は、主にVernoのデータベースの設計に起因している。そこで、これらの問題を解決し、かつ、Vernoの特徴をより前面に打ち出したシステムが作れないものかと考えた。
本研究では、早稲田大学内の約 97000ページを対象とし、従来のVernoで用いられていた主なデータ、あらゆる文字列検索を可能にする 1-Gram方式インデクス、そして、SXMLデータを、Schemeにネイティブな形で共有メモリセグメント上へ展開した。主記憶検索言語は Scheme処理系 SCMをベースとし、従来と互換を残すプリミティブ関数や、SXMLデータを利用するための実装を行った。そして、幾つかの検索例を通して、有用性と速度面の向上を示す事が出来た。
1http://verno.ueda.info.waseda.ac.jp/

第1章 研究の背景と目的
1.1 研究の背景
1.1.1 全文検索システムVerno
今日、WWW上には様様な情報が溢れている。全文検索システムの利用はそのリソースを有効に活用するための一つの手段であり、Vernoもそのような全文検索システムの一つである。Vernoは「プログラマブルな検索エンジン」をコンセプトとしており、プログラミング言語 Schemeで検索クエリーを記述できる特徴を持っている。
Vernoは対外的なサービスを行っているが、一般的な商用サーチエンジンと比べ、様々な面で大きく遅れをとっている。対象ページ数や更新頻度、出力順などに限って言えば、Vernoの魅力は年々、急速に薄れている事を否定できない。
しかし一方で、複雑な検索を出来るという面から考えると、ユーザーが複雑な検索を対話的に行う事が出来るという独自の、そして大きな特徴が、Vernoには存在している。
1.1.2 Vernoの検索言語が抱えていた課題
Vernoの検索言語として、verno-elkと verno-scmが存在している。これらは、次の問題を抱えていた:
問題点 1:Schemeならではのデータがシステムで用意されていないverno-elkおよび verno-scm上から利用できるデータは、いずれもディスク上の
専用ファイルに格納されており、そのアプローチはリレーショナル・データベースに近いものであった。Schemeならではのデータとして、Vernoでは SXMLデータが着目され、その有用性を示す研究が行われた。[wei] しかしながら、本格的にシステムに組み込むま
1

でには至っていなかった。これは、SXMLが半構造化データであり、従来と同じ形式でのデータベース化が困難であったためである。
問題点 2:データを得るための関数がわかりにくいVernoのデータがほぼ、リレーショナル・データベースに近い形で格納されて
いたため、これらのデータを利用する際に用いられる Scheme関数も、ハンドラを open,read,closeするなど、Schemeプログラマにとって若干、複雑な設計となっていた。
問題点 3:処理系のサーバ化が考慮されていない検索言語は Inetdを利用して、検索要求の処理を行っている。クエリーを受け
付けるたびに発生するデータベースの初期化作業のコストと、複数の処理系が使用する主記憶の量、が問題となっていた。
これらの問題点を解決する事が、本研究の目的となる。
1.2 研究の目的これらの問題点を解決するためには、SXMLデータを初めとするVernoのデー
タを、Scheme処理系の内部データ表現の形で、共有メモリセグメント上に展開する手法が考えられる。これにより、SchemeプログラマがVernoのデータを扱いやすくなり、また、Inetdを利用する事で発生していた問題点も解決される。
以上の背景を踏まえて、Scheme処理系 SCMをベースに、主記憶検索言語の設計と開発を行う。対象となるデータは、早稲田大学内約 97000ページのHTML文書から作成される、従来のVernoの主なデータ、1-Gramインデクス、そして SXML
データとする。
そして、実装した主記憶言語での検索例を通して、その有用性や速度面について考察を行う。主記憶検索言語の開発によって、Schemeが名実共にVernoの主役になる事を期待している。
2

1.3 本論文の構成本論文では、次の第 2章で、関連研究について述べる。第 3章ではVernoと主記憶検索言語の説明、そして全体の設計について説明する。第 4章では実装の詳細について述べ、第 5章では使用方法、使用例の紹介を行う。これをふまえて第6章では、主記憶検索言語の処理能力や有用性について考察する。最後に、第 7
章で今後への課題を取り上げ、まとめとする。
3

第2章 関連研究
本章では初めに、本研究のベースとなるプログラミング言語 Schemeと、その関連研究/技術を紹介する。そして、XMLデータベースや商用サーチエンジンなど、類似のシステムについて触れ、本研究との位置付けの違いを述べる。
2.1 プログラミング言語Scheme
Guy Lewis Streel Jr.と Gerald Jay Sussmanによって開発された Schemeは、主に次の特徴を持ったプログラミング言語である。
1. プログラミング言語 Lispの主要な方言
2. 継続、静的スコープを持ち、真正に末尾再帰的
3. 開発効率の高い関数型言語
4. 高い対話性
5. S-expression、優れたリスト処理
6. Garbage Collection
Schemeの言語仕様は Revised5 Report on the Algorithmic Language Scheme
[6] にまとめられている。なお、Vernoの初期の開発者が、Schemeを検索言語として利用した理由としては「複雑な処理(検索要求)を簡単に書ける事」「処理系がインタープリタである事」の 2点が挙げられており、これらは上記の特徴の 3と 4にあたる。
2.1.1 Scheme処理系SCM
Aubrey Jaffer氏によるSCMは、Revised5 Report on the Algorithmic Language
Scheme およびANSI /IEEE標準規格 [7]に準拠した、Scheme処理系の実装である。数ある Scheme処理系の中で、SCMは最も高速なものの一つとして知られている。SCMはC言語によって記述されており、Linux/FreeBSD/Windowsを初めとする、様々なプラットホームでの動作が確認されている。
4

更に、SCMには Scheme-to-C compilerである hobbitが付属する。この hobbitの利用によってプログラマは、Schemeで書かれた関数の最適化を行う事が可能である。また Jaffer氏は Scheme用のライブラリ SLIBの開発でも知られ、SLIBは SCM
を初めとする多くの Scheme処理系上で利用されている。Vernoと関連した SCMの特徴としては、EUC JPで書かれた日本語が利用できる事や、C言語による Schemeのプリミティブ関数の実装が行える事などが挙げられる。
2.1.2 SXML
Oleg Kiselyov氏による SXMLは (S-expressed XML)、XMLの抽象構文の一種である。XMLの持つタグ構造は、SXMLにおいて S式 (Symbolic Expressions)で表現される。ここではXHTMLデータを、SXMLで表記する例を示す。なお、XHTML(eXtensible
HyperText Markup Language)とは、XMLのサブセット仕様であり、Webページを記述するためによく使われるHTMLを、XMLに適合するように定義し直したマークアップ言語である。XHTMLやXMLでは、タグを入れ子(ネスト)にしてデータ構造を記述する。
<head> <title> </title> </head>
この入れ子構造は次のように
<head> <title> </head> </title>
クロスしてはならない。このルールによって、XMLデータは木構造で表現出来る事が保証されている。
XHTML¶ ³<?xml version="1.0"?><!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"><html xmlns="http://www.w3.org/1999/xhtml"><head><meta http-equiv="Content-Type" content="text/html; charset=EUC-JP" /><title>タイトル文字列</title></head><body bgcolor="white" textcolor="#333333">本文ここから<br /><b>ボールド</b><br />本文ここまで<br /></body></html>
µ ´
5

SXMLでは次のように表現される。SXML¶ ³
(*TOP*(*PI* xml "version=\"1.0\"")(http://www.w3.org/1999/xhtml:html(http://www.w3.org/1999/xhtml:head(http://www.w3.org/1999/xhtml:meta(@ (http-equiv "Content-Type")
(content "text/html; charset=EUC-JP")))
(http://www.w3.org/1999/xhtml:title "タイトル文字列"))(http://www.w3.org/1999/xhtml:body(@ (textcolor "#333333") (bgcolor "white"))"本文ここから"(http://www.w3.org/1999/xhtml:br)(http://www.w3.org/1999/xhtml:b "ボールド")(http://www.w3.org/1999/xhtml:br) "本文ここまで"(http://www.w3.org/1999/xhtml:br)
))
)µ ´このようなXML->SXMLの変換を行うツールとしては、Oleg氏によって SSAX
が実装されている。そしてこの SXMLデータは、若干の変更を加える事で、そのまま Schemeのデータとしてロードする事が可能である。このように、プログラミング言語 Scheme
とXMLは非常に親和性が高い。Vernoにおいてもこの親和性の高さは注目されており、過去にその指摘がされてきた。[tk] Vernoが対象とする HTML文書を SXML化し、そのデータを加工する研究も過去に行われている。[wei] しかしながら、本格的にシステムに組み込むまでには至っていなかった。
2.1.3 SXPath
Oleg Kiselyov氏らによって開発された SXPathは、SXMLのためのクエリ言語である。その全てを紹介する事は出来ないので、ここではXPathクエリーとの対応を示す。
6

SXPath¶ ³
ここに何を載せるべきか。まだ決まっていない。
(sxpath ’(para)) コンテキストノードの子要素である para
(sxpath ’(*)) コンテキストノードの全ての子要素(sxpath ’(*text*)) コンテキストノードの子の全てのテキストノード(sxpath ’(*any*)) コンテキストノードの全ての子供 (何でも)
(sxpath ’(* para)) コンテキストノードの全ての子孫の para
(sxpath ’(@ name)) コンテキストノードの name 属性(sxpath ’(@ *)) コンテキストノードの全ての属性(sxpath ’(// para)) コンテキストノードの子孫のうちの para
(sxpath ’(//)) コンテキストノード自身とその子孫全て(sxpath ’(div // para)) コンテキストノードの子の div 要素の子孫のうちの para
(sxpath ’(// td @ align)) 全ての td 要素の align 属性(sxpath ’(// (td (@ align)))) 属性 align を持つ全ての td 要素(sxpath ’(// (td (@ (equal? (align "right"))))) 属性 align が"right"である全ての td 要素(sxpath ’((para 1))) コンテキストノードの最初の子の para
(sxpath ’((para -1))) コンテキストノードの最後の子の para
(sxpath ‘(,(node-parent tree) @ name)) コンテキストノードの親の属性 name
(sxpath ’(table (tr 2) (td 3))) table の 2 番目の tr の 3 番目の td
日本語だと、http://makoto.homeunix.org/cgi-bin/wiliki.cgi?SXML%3ASXPath%3AAbbrPath&l=jp
の表が一番よくまとまっている。µ ´その他の SXMLクエリー言語としては、Oleg氏らによるクエリー言語 SXSLT
の実装が存在している。なお、本研究では SXPathのみを利用する。
2.2 情報検索システム世の中の情報検索システムについての調査。XMLデータベース主記憶データ
ベースリレーショナルデータベース処理系+リレーショナルデータベース
7

第3章 主記憶検索言語の設計
本章では初めに、Vernoにおける従来の検索言語について、その問題点や特徴を、本研究のコンセプト等を交えて紹介する。その上で、本研究で実装したソフトウェアの設計を紹介する。全体のソフトウェア構成は、図 3.2とする。最後に、研究に用いたデータやハードウェアの詳細を紹介する。
3.1 Vernoにおける検索言語これまでVernoでは、主にVerno-Elkと fhandleと呼ばれる検索言語を用いてきた。(図 3.1)
verno-elkは、Scheme処理系 Elkをベースに、Vernoのデータを扱う関数を追加した Scheme処理系である。verno-elkは Schemeで記述された検索要求を処理する事が可能であるものの、その基本的な処理速度やメモリ管理の問題から、実験的な利用に留まっている。verno-scmは SCMベースの Scheme処理系であり、現在 verno-elkからの移行作業が続けられている。verno-elkと verno-scmが、既存の Scheme処理系に検索機能を付け加えた検索言語であるのに対して、fhandleは実用性を重視して設計されている。fhandleは指定されたフォーマットで高速に検索結果を出力する機能に特化されており、自身で検索結果の加工を行う機能を持たず、複雑な処理は行えない。主に、CGI経由のキーワード検索に用いられている。
8
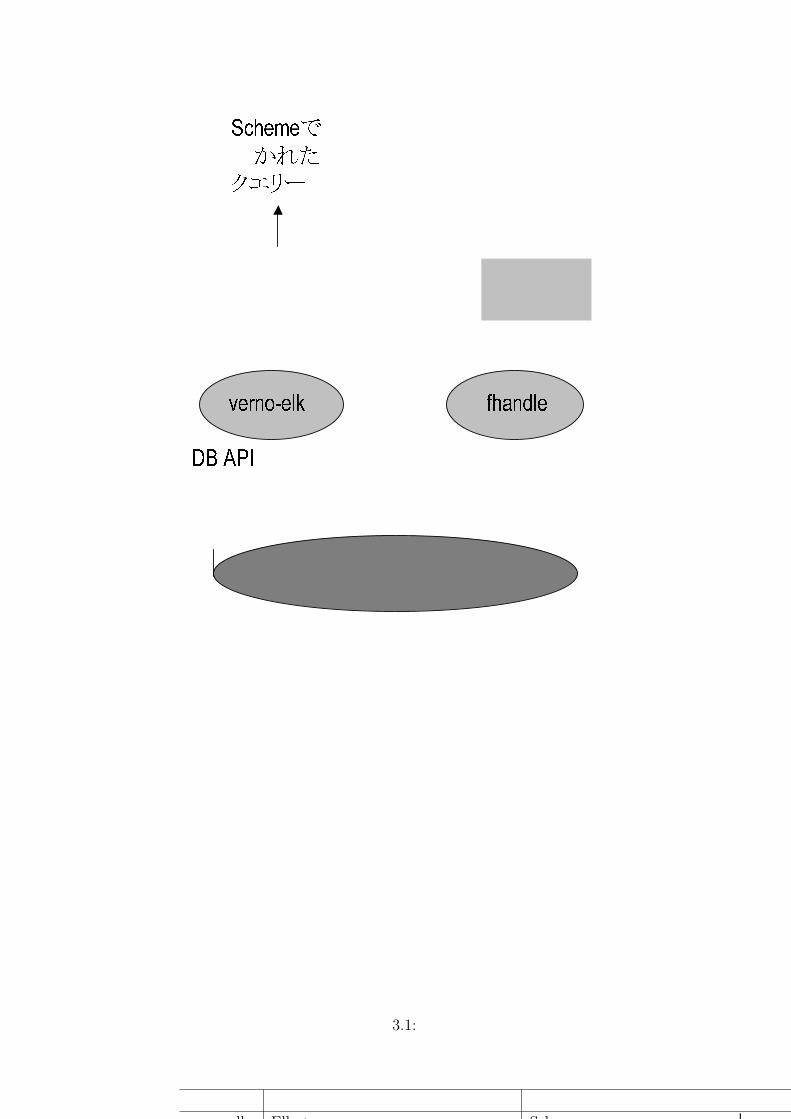
DB APIverno-elk fhandle
Schemeで書かれたクエリーCGI
クエリー(キーワード)
各種DBファイルDB API
Internet ServiceDaemon
図 3.1: 従来の検索言語
名称 特徴 用途verno-elk Elk + 検索のための関数 Schemeで書かれた複雑なクエリーの処理
fhandle サーバープログラム CGI経由でキーワード検索の処理用途を特化し、高速化を図っている
verno-scm SCM + 検索のための関数 Schemeで書かれた複雑なクエリーの処理verno-elkよりは高速
9

3.1.1 inetdからの起動
inetd(Internet Service Daemon)は、指定されたポートへのアクセスがあった時に指定されたプロセスを起動し、プロセスの標準入出力をそのポートに結びつけるプログラムである。Vernoの 3つの検索言語の内、verno-elkおよび verno-scm
は、この inetdを利用して検索要求の処理を行っている。データベースマシン内部における、検索時の処理の流れを示す。
処理の流れ (従来)¶ ³
1. inetdが 9999番ポートへの接続を確認すると、2の処理を行う。
2. inetdが verno-elk(又は verno-scm,以下略)を起動する。接続要求の数だけ、verno-elkのプロセスが立ち上がる。
3. verno-elkは、データベースの初期化作業 (ハンドラを open)を行う。この時Cのmmap関数によって、ディスク上のファイルのメモリ上へのマッピングが試みられる。
4. Schemeで書かれたクエリーが実行される。
5. verno-elkは、ユーザーによる exit関数、又は接続の切断によって終了する。
µ ´この方式による問題点は以下の 2点が考えられる。
• 問題点 1. 各プロセスが個別にファイル内のデータを主記憶上に展開するという無駄が発生している。
• 問題点 2. クエリーを受けた後に処理系が起動するため、mmapを行う意味が殆ど無い。必ず、ディスクアクセスが発生する。
上記の内、1の問題点を端的に表すものとして、約 10万ページを対象とする早稲田版データベースマシンにおいて、psコマンドを実行した結果を以下に示す。¶ ³
%ps axu -U nobody
USER PID %CPU %MEM VSZ RSS TT STAT STARTED TIME COMMAND
nobody 8360 35.1 0.3 782644 3332 ?? Rs 12:00PM 0:26.60 verno-elk -l -
nobody 8353 28.7 0.3 782644 3332 ?? Rs 11:59AM 0:15.35 verno-elk -l -
nobody 8350 27.6 0.3 782644 3332 ?? Rs 11:59AM 0:13.00 verno-elk -l -
nobody 8340 0.0 0.1 3244 932 p1 S+ 11:58AM 0:00.00 elk
nobody 103 0.0 0.2 780540 1584 con- S 271203 0:36.18 /usr/local/bin/fhandle
server:9090 (fhandle_nagasawa)
µ ´ここでは、3つの Schemeで書かれたクエリーを同時に処理している。PID8340
のプロセスは、比較のために起動したプレーンな Scheme処理系 elkである。比
10

較すると、verno-elkプロセス (PID8350,8353,8360)の仮想メモリのサイズが非常に大きい事が確認出来る。
3.2 主記憶検索言語の設計全体の設計を図 3.2に示す。従来の Vernoが用意していたデータに加えて、あらゆる文字列検索を可能にする 1-Gram方式インデクスと、SXMLデータを共有メモリセグメント上に展開する。
3.2.1 処理の流れ
検索時の処理の流れは、以下のようになる。処理の流れ¶ ³
1. 準備段階として、uni-gramインデクス / SXMLデータ /その他のデータ をディスクから読み込み、共有メモリセグメントに展開する。この処理は一度だけ行う。
2. inetdが 9999番ポートへの接続を確認すると、3の処理を行う。
3. inetdが Scheme処理系 scmを起動する。接続要求の数だけ、scmのプロセスが立ち上がる。
4. scmは起動時に、共有メモリセグメントをReadOnlyでAttachする。SXMLデータは、変数wasedaにバインドされる。
5. Schemeで書かれたクエリーが実行される。
6. scmは、ユーザーによる exit関数、又は接続の切断によって終了する。µ ´
3.2.2 共有メモリ
通常、プロセスが確保したメモリ領域は、他のプロセスからアクセスする事は出来ない。共有メモリは、複数のプロセスが同じメモリ領域へアクセスするための技術である。本研究では、System V InterProcessCommunication(プロセス間通信,以下 IPC)
の shmat,shmget関数を利用した。System V IPCは、メッセージキュー (message
queue)、共有メモリ (shared memory)、セマフォ(semaphore) から構成され、多
11
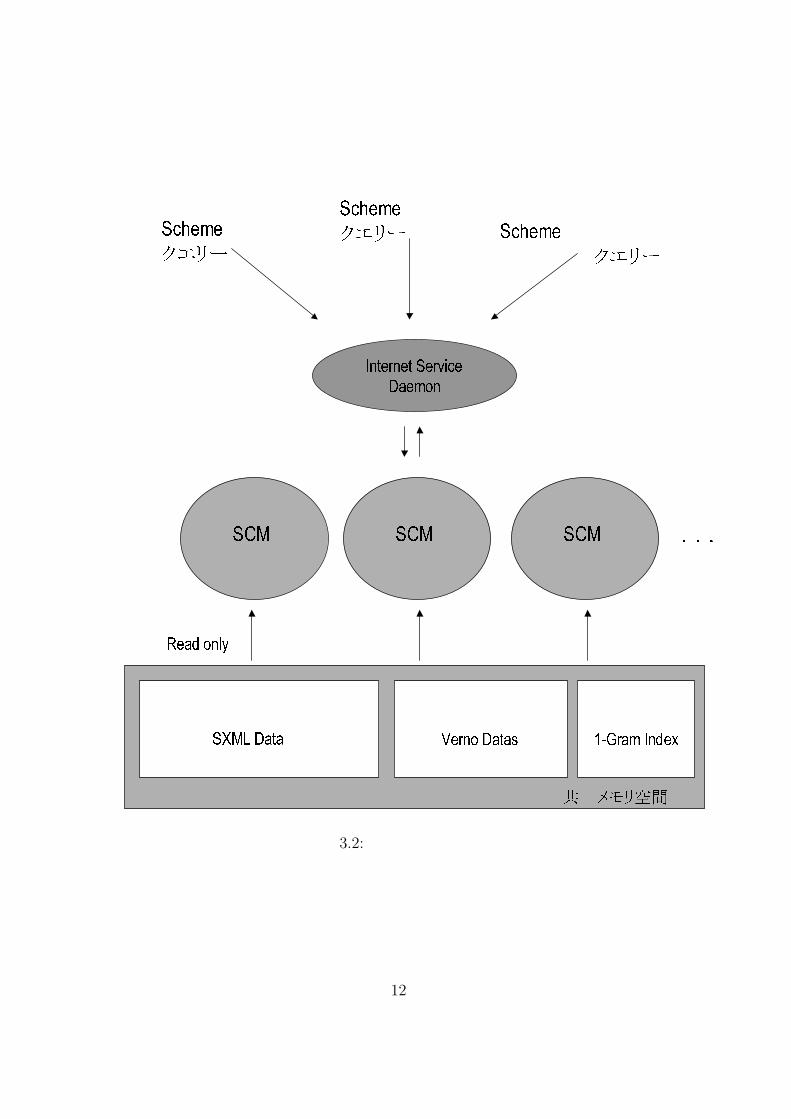
SCM
共有メモリ空間SXML Data Verno Datas 1-Gram Index
............SCM SCM
Read only
Internet ServiceDaemon
Schemeで書かれたクエリーSchemeで書かれたクエリー Schemeで書かれた クエリー
図 3.2: 主記憶検索言語
12

くのUnix系OSにおいてサポートされている。
3.2.3 扱うデータ
共有メモリセグメントに展開するデータについて述べる。
1-Gramインデクス
従来の Vernoでは、2-Gram,3-Gram方式を用いた沼尻氏のインデックスデータベース(以下インデックスデータベース)を用いてきた。インデックスデータベースは、主に 3文字以上の日本語の単語を検索する際の最適化がなされており、全文検索システムVernoのエンジンとして高速な文字列検索を提供してきた。
しかしながらインデックスデータベースは、
・200万ページ以上のページのインデクシングが困難。・nが 2と 3で固定であり、長さが 1文字である単語の検索が出来ない。
等の問題も抱えていた。
現在、Vernoでは新たなインデクサの開発が進められているが、本研究では 1-
Gramインデクスの試験的な導入を行った。1-Gramインデクスを利用する事で、従来のVernoで不可能だった日本語一文字検索が可能となる。
新たな n-Gramインデクサでは、1~7Gram インデクスを作成および利用する事が可能であるが、本研究では、共有メモリセグメントのサイズを抑える事を考え、1-Gramインデクスだけを利用するものとした。今後、VISA(Verno Index Suffix Array)[kakky2003]データを利用する実装を行う事を前提に、本研究では、1-Gram文字列検索の速度についての考慮を一切行わない。
SXMLデータ
各ページの SXMLデータはリスト構造によって表現され、全てのページはリストによって連結される。その上で全体を管理するリストは、変数 wasedaにバインドされる。(図 3.3)
したがって、ユーザーは次の式によって、各ページの SXMLデータを直接、利用する事ができる。
13
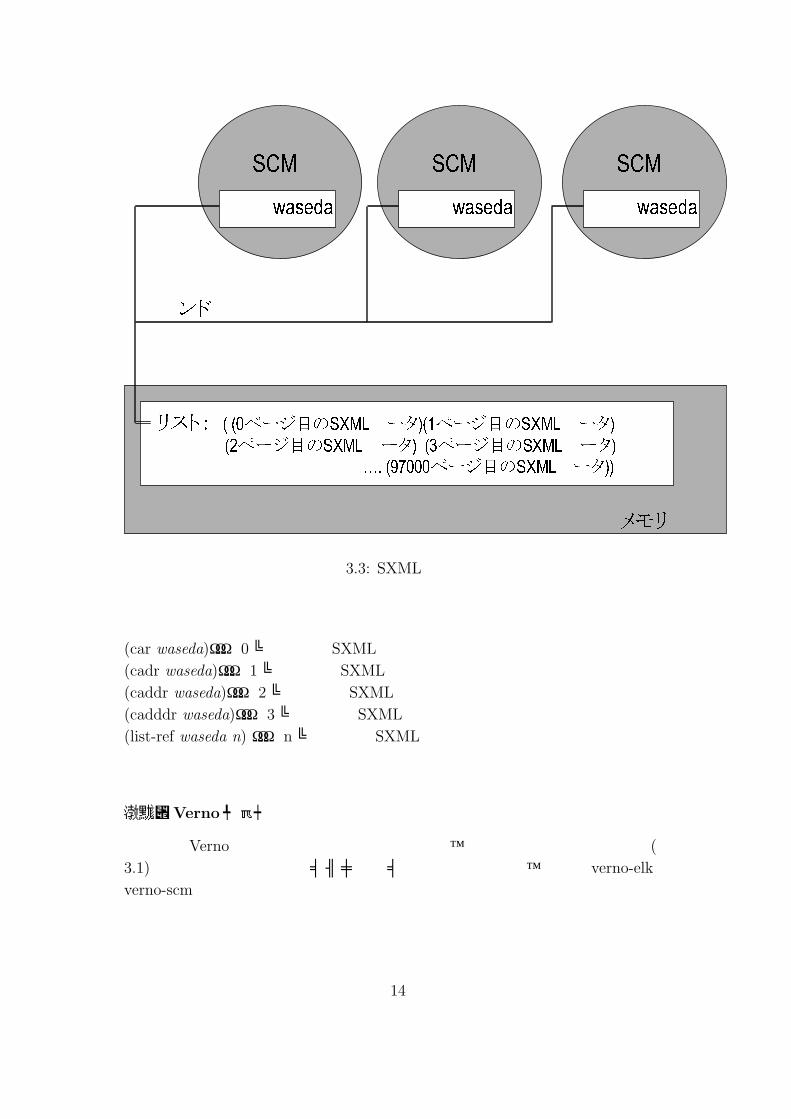
リスト: ( (0ページ目のSXMLデータ)(1ページ目のSXMLデータ)(2ページ目のSXMLデータ) (3ページ目のSXMLデータ)…. (97000ページ目のSXMLデータ))
SCM
バインド
共有メモリ空間
SCM SCM変数 waseda 変数 waseda 変数 waseda
図 3.3: SXMLデータ
(car waseda)・・・ 0ページ目の SXMLデータ(cadr waseda)・・・ 1ページ目の SXMLデータ(caddr waseda)・・・ 2ページ目の SXMLデータ(cadddr waseda)・・・ 3ページ目の SXMLデータ(list-ref waseda n) ・・・ nページ目の SXMLデータ
従来のVernoデータ
従来の Vernoで用いられていたデータのうち、主だったものを提供する。(表3.1) これらのデータは共有メモリセグメント上に展開され、従来の verno-elkやverno-scmと同じ関数で利用可能となる。
14

名称 説明url URL文字列。dig XHTML文書のタグ部を取り除き、さらに空白や改行を取り除いた文字列。title タイトルタグに挟まれた文字列。link リンクの情報。
表 3.1: Vernoデータ
3.3 本研究の対象データページ収集プログラム Larbinにて収集を行った。Sebastien Ailleret 氏による
Larbinは、平均的な PCで一日 5000万ページを収集可能とする、フリーのプログラムである。
収集プログラム larbin-2.6.3
収集日 11月 29日 01:57 ~ 11月 30日 06:06
対象1 .waseda.ac.jpドメイン総ページ数 97924
表 3.2: 収集データ
3.4 用いたハードウェアとオペレーティングシステム本研究では、8GBのメモリを積んだ 32bit機を用いた。そのスペック (表 3.3)
と、オペレーティングシステムの情報、用いたコンパイラのバージョンなどを示す。
15

パーツ パーツ名 数量
CPU Intel Xeon 2.4GHz FSB533 2
マザーボード SuperMicro X5DPE-G2 1
メモリ Transcend DDRSDRAM 1GB ECC REG 8
HDD MAXTOR MX-4R080L0 FLUID 80GB 1
ケース VAV CS-710電源なし 1
電源 Antec TruePower 550 EPS 12V 1
CD-ROM AOPEN CD-956E Bulk 1
FDD Mitsumi D359M3 1
表 3.3: 本研究において用いたマシンのスペック
¶ ³%uname -aLinux paneer 2.4.20-8bigmem #1 SMP Thu Mar 13 17:32:29 EST 2003i686 i686 i386 GNU/Linux
%cat /etc/fedora-releaseFedora Core release 1 (Yarrow)
%ipcs -lm------ シェアードメモリの制限 --------セグメント数の最大値 = 4096セグメントサイズの最大 (単位:KB) = 2097152max total shared memory (kbytes) = 8388608最小セグメントサイズ (単位:KB) = 1
%rpm -q gccgcc-3.3.2-1
%rpm -q scmscm-5d9-1.i386.rpm
µ ´
16

第4章 主記憶検索言語の実装
本章では、実装したソフトウェアについて、
1. 収集したHTML文書を、必要な形式のファイルへ変換するまで
2. 1.で用意したファイルを、共有メモリセグメント上に展開するまで
3. 2.で展開したデータを、SCM上から利用するまで
の 3つの過程に分け、詳細に述べる。
4.1 ファイル変換収集したHTML文書を、検索言語で用いるデータに変換するまでの過程の概略を図 4.1に示す。
4.1.1 larbin2xml
larbinが収集したHTML文書を、XML文書に変換するためのスクリプト larbin2xml
を用意した。スクリプトは、文字コード変換プログラム nkfと、HTML整形ツール tidyを呼び出している。XHTML文書の文字コードは、UTF-8へ変換される。
4.1.2 xml2verno
XMLファイルから、タグを取り除いた文字列、タイトルタグに挟まれた文字列、および、リンクの情報を抽出するプログラムを実装した。このプログラムは、従来以上に大規模なページ数に対応したファイル形式での出力を行う事が可能であるが、今回は従来のVernoと互換を残した出力形式で、出力を行った。出力されたファイル内の、文字列の文字コードは EUC JPとなっている。
17
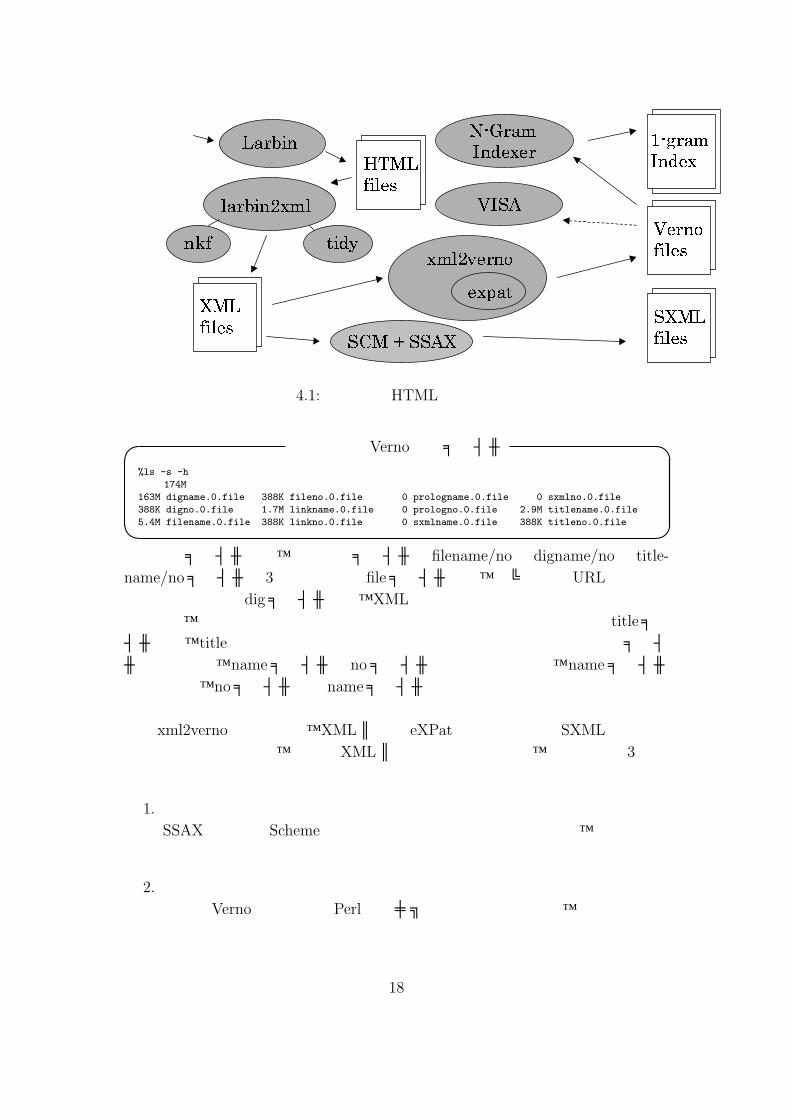
WWW Larbinlarbin2xmlnkf tidy xml2verno
HTMLfiles
XMLfiles expatSCM + SSAX SXMLfiles
VernofilesVISAN-Gram Indexer 1-gramIndex
図 4.1: 収集したHTML文書の加工
出力されたVerno形式ファイル¶ ³%ls -s -h
合計 174M
163M digname.0.file 388K fileno.0.file 0 prologname.0.file 0 sxmlno.0.file
388K digno.0.file 1.7M linkname.0.file 0 prologno.0.file 2.9M titlename.0.file
5.4M filename.0.file 388K linkno.0.file 0 sxmlname.0.file 388K titleno.0.file
µ ´これらのファイルの内、利用するファイルは filename/no digname/no title-
name/noファイルの 3種類となる。fileファイルには、各ページのURL文字列が保存されている。digファイルには、XML文書内におけるタグではない部分の文字列から、さらに空白や改行などを取り除いた文字列が保存されている。titleファイルには、titleタグに挟まれた部分の文字列が保存されている。各種類のファイルはそれぞれ、nameファイルと noファイルの対になっており、nameファイルにデータが、noファイルには nameファイル内での区切りの位置が格納されている。なお xml2vernoの実装には、XMLパーザ eXPatを用いている。SXMLデータを用意したにも関わらず、あえてXMLパーザを用いた理由は、主に以下の 3点である:
1. 高速化を図るためSSAXを用いて Scheme処理系上で処理する事も考えられるが、倍以上の処理速度の差がある。
2. タグ部抽出の精度を高めるため従来のVernoでは簡単なPerlスクリプトを用いていたため、抽出が不正確であった。
18

3. SXMLや Prolog形式での出力が容易であるため将来的に、このコマンドで直接 SXMLや Prolog形式の出力を行う事を考えた。
4.1.3 xml2sxml
XML文書の SXML文書への変換には SSAXパーザを用い、下記の関数を各ページに適用した。
SSAXの利用¶ ³
(write (SSAX:XML->SXML (open-input-file INPUTFILE) ’()) (open-output-file OUTPUTFILE))
µ ´
4.1.4 1-Gramデータ
1-Gramデータは、新たに開発した n-Gramインデクサを用いて作成した。なお、用いた内部文字コードは EUC_JPである。
1-Gramインデクスファイル¶ ³
%ls -s -h合計 396M44K 1gram.hash.bin 396M 1gram.index 24K 1gram.pos
µ ´
19

4.2 共有メモリセグメントへの展開次に、データをどのように共有メモリセグメントへ展開したか、その実装について述べる。
4.2.1 Schemeのデータ型とその内部表現
作成した SXMLデータを検証した結果、SXMLデータはリスト、symbol型、string型のみで構成されている事を確認した。すなわち、タグ構造はリストで、タグ名は symbol型で、その他の文字列は string型で表現されている。この 3つに加えて、Vernoのページ番号などを表すため number型を用いた実装を行った。実装の説明に先立ち、SCMにおけるこれらの型の内部データ構造について、例を挙げて簡単に説明する。
symbol型、string型、そして number型を含んだ、次のリスト:
(’symbol "string"(1 2 3))
は、メモリ内部では図 4.2のように表現される。
1
EOL
“symbol” “string”2 3 EOL
図 4.2: (’symbol ”string”(1 2 3))
SCMでは、number型は SCM型で表現される。symbol型、string型、およびリストは、cell構造体 (以降セル) によって表現される。SCMにおけるセルとは、SCM型を 2つ並べた対 (CARとCDR)であり、本研究の環境では、32bitの long
型を並べた対であった。
リストを表現するセルは consセルと呼ばれ、CAR部とCDR部にそれぞれ、SCM
型のデータ、又はセルへのポインタが格納されている。symbol型と string型は、CDR部にその名前を示す文字列へのポインタが、CAR部に文字列の長さとシン
20

ボルを表すタイプコードを格納したセルによって表現される。なお、SCMにおいてデータがセルであるかどうかの判定を行うマクロは、scm.h
の中で次のように定義されている。セルであるかどうかの判定を行うマクロ¶ ³
#define CELLP(x) (!NCELLP(x))
#define NCELLP(x) ((sizeof(cell)-1) & (int)(x))µ ´
4.2.2 SXMLデータ
SXMLデータ領域
共有メモリセグメント上で、SXMLデータを置くための領域を、主に 3つの領域に分ける実装を行った。一つは、主にリスト構造を展開する領域であり、残りは可変の文字列データを展開するための領域である。以降、リスト構造を保存する領域を sxmldata領域、タグに挟まれた文字列部を保存する領域を sxmldig領域、タグ名を保存する領域を sxmltag領域とする。
sxmldata領域には、先頭からセルのみが並べられる。sxmldata領域は、そのアドレスを SCM型へキャストした時に下位 3ビットが 0となる位置を、先頭としている。これは、SCM処理系が、sxmldata領域に置かれた各セルを、セルとして認識するための措置である。この領域には、consセルと、string型および symbol型を表現するセルのみが並ぶため、領域の殆どがポインタとタイプコードによって占められる。
sxmldig領域には、SXMLデータ中に出現する、タグに挟まれた文字列部が展開される。C言語の char型が出現した順に先頭から並ぶ形であり、圧縮などの特別な処理は行っていない。非タグ部の文字列については、ダイジェストの表示やインデクシングを行うための digと呼ばれるデータも共有メモリセグメント上に展開されるが、空白や改行の除去などの処理を行っていない点で、digとは若干異なっている。
sxmltag領域には、SXMLデータ中に出現する、タグの名前を表す文字列が展開される。SXMLにおいては、タグ名は Schemeの Symbol型で表現されており、タグ名が重複して保存される事を防いでいる。通常、SCMにおいては内部で次の処理を行い、シンボルを作成している。
1. シンボル名が既に利用されているかを、ハッシュテーブル (以下 symhash)
で確認する。
21

・symhashに登録が無ければ、シンボル名を表す文字列を保存し、 その位置をハッシュテーブルに登録する。 ・symhashに登録があれば、文字列は既に保存されているので、 そのアドレスを得る。
2. CAR部に文字列の長さとシンボルを表すタイプコードを、CDR部に文字列へのポインタを格納したセルを作成し、シンボルを表現する。
一方で主記憶言語においては、sxmldata領域上でシンボルを表現するため、以下の処理を行う実装とした。
1. あらかじめ、全てのシンボル名 (タグ名)を抽出しておき、重複を除いてsxmltag領域にコピーする。
2. キーをタグ名、データを sxmltag領域におけるタグ名の出現位置、としたハッシュテーブルを作成する。
3. sxmldata領域内で出現するシンボルは、CAR部に文字列の長さとシンボルを表すタイプコードを、CDR部に sxmltag領域内の文字列へのポインタを、それぞれ格納したセルで表現する。
SXMLデータの展開
SCM上で取り扱う SXMLデータは、下記の手順で共有メモリセグメントへ展開される。
1. 97001個の空リストを要素とするリストを作成し、各ページに対して 2-4の処理を行う。
2. SCMの load関数を用い、1ページ分のデータをヒープ上に展開する。
3. 展開したデータを、ポインタ構造を保持したまま、共有メモリセグメントにコピーする。
4. 長さ 97001のリストと、コピーしたデータをポインタで連結する。
1の処理は Scheme関数 shm-sxml-initによって行われ、3と 4の処理は Scheme
関数 shm-sxml-loadによって行われる。
4.2.3 その他のデータ
URL文字列など、従来のVernoで用いていた可変長データに関しては、ファイル内でのデータ構造のまま、共有メモリセグメントへ展開した。
22
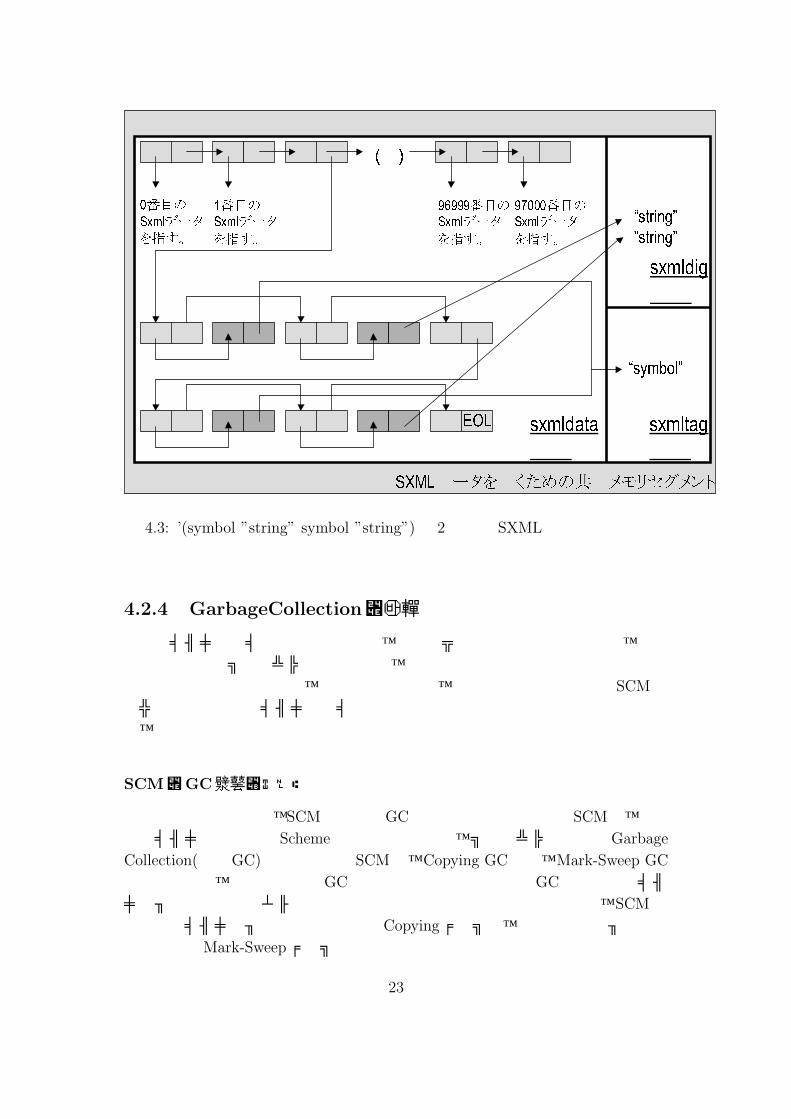
SXMLデータを置くための共有メモリセグメント
(略)0番目のSxmlデータを指す。 1番目のSxmlデータを指す。 96999番目のSxmlデータを指す。 97000番目のSxmlデータを指す。
sxmldata領域 sxmltag領域
sxmldig領域“string””string”
“symbol”EOL
図 4.3: ’(symbol ”string” symbol ”string”)を 2番目の SXMLデータとして格納する例
4.2.4 GarbageCollectionの回避
共有メモリセグメント上のデータは、複数のユーザーが検索を行ったり、検索結果を加工するプログラムの書くための、材料として用いられる。したがって管理者の明示的な操作を除いて、書き換えられたり、消去されてはならない。SCMのコレクタによる共有メモリセグメント上のデータ書き換えを回避するために行った、実装について述べる。
SCMのGC処理について
実装の説明に先立ち、SCMにおけるGC処理を簡単に説明する。SCMは、自動的なメモリ解放を行う Scheme処理系であるので、プログラム実行中にGarbage
Collection(以下GC)が行われる。SCMは、Copying GC法と、Mark-Sweep GC
法を併用した、いわゆる世代GC方式を採用している。世代GCは「新しいメモリオブジェクトほどゴミになりやすい」という特性を活かした方式で、SCMでは新しいメモリオブジェクトのためのCopyingヒープと、そうでないオブジェクトのためのMark-Sweepヒープが用意されている。
23

SCMにおける、GCアルゴリズムの概略を示す。
1. Copyingヒープ (ecachev)、又は、root setが埋まったら、Copyingヒープに対して、Copying GC (2.)が行われる。
2. Copying GC : 参照されているオブジェクトを全て、ポインタ構造を保持したまま、Mark-Sweep ヒープにコピーする。
3. Copying GCにて十分な領域が確保されなかった場合、Mark-Sweep ヒープとCopying ヒープに対して、Mark-Sweep GC(4.および 5.)が行われる。
4. Mark-Sweep GC, Marking Phase : 到達可能なオブジェクトを全てマークする。
5. Mark-Sweep GC, Sweeping Phase : マークされたオブジェクトを Sweepし、freelistに登録する。
GCの回避
SCMのMark-SweepコレクタはMarking Phase時に、ポインタを辿りセルのマークを行っている。実際にマークを行う関数 gc markは、マークを行うセルの中に別のセルへのポインタを発見すると、ポイント先のセルを引数とし、自身を再帰的に実行する。この再帰呼び出しは、次の 2つの条件が満たされている時に発生する。
• 条件 1:ポイント元のセルが、まだマークされていなかった。
• 条件 2:ポイント先がセルである。
sys.c¶ ³2483 gc_mark_nimp:2484 if (NCELLP(ptr)2485 /* #ifndef RECKLESS */2486 /* || PTR_GT(hplims[0], (CELLPTR)ptr) */2487 /* || PTR_GE((CELLPTR)ptr, hplims[hplim_ind-1]) */2488 /* #endif */2489 ) wta(ptr, "rogue pointer in ", s_heap);
µ ´ポイント先が、ヒープの外であるかのチェックは行われていない。(ソースではコメントアウトされている)したがって、SCMのコレクタは、ヒープの外へのポインタであっても辿ってしまう。
24
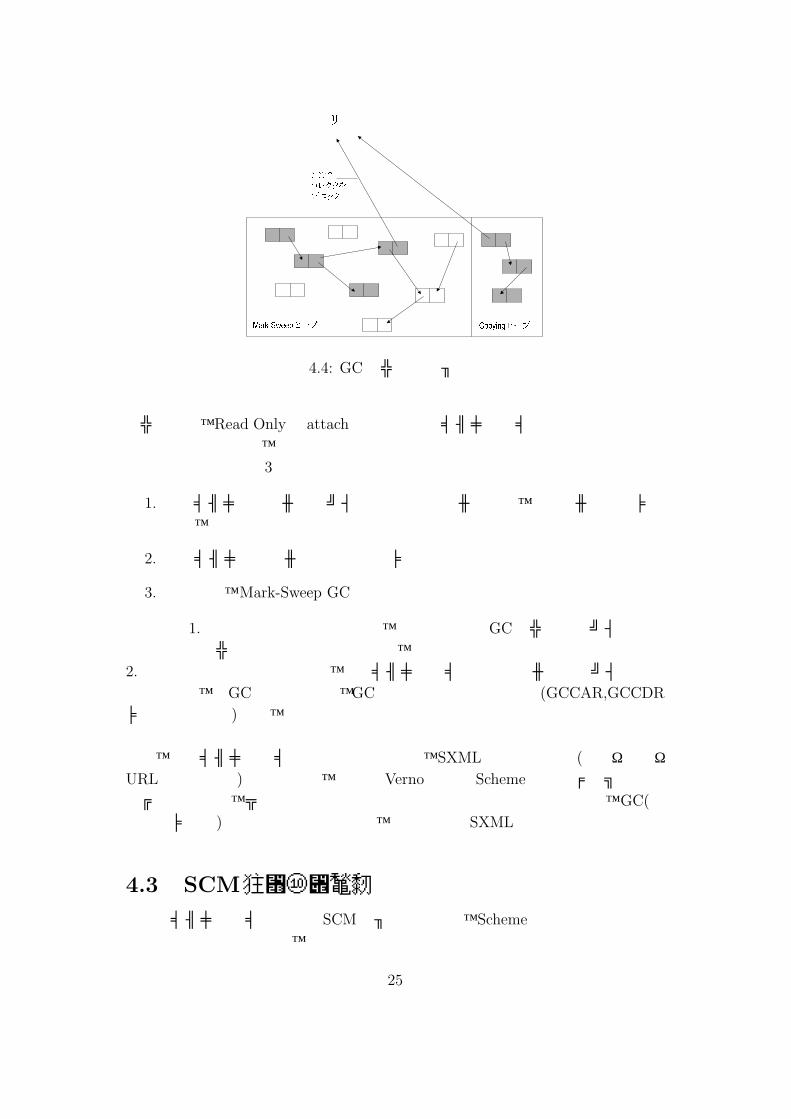
Copying ヒープMark-Sweep ヒープ
共有メモリここでコレクタをブロック
図 4.4: GCコレクタのブロック
コレクタが、Read Onlyで attachしている共有メモリセグメント上のデータを書き換えようとすると、処理系が不正終了してしまう。この解決方法として 3つの手法を考えた:
1. 共有メモリ上のセルへのポインタを持ったセルの場合、そのセル自体はマークし、そこから先は辿らないようにする。
2. 共有メモリ上のセルをあらかじめマークしておく。
3. そもそも、Mark-Sweep GCを行わせない。
現在は 1.の手法での実装を行ったが、この手法ではGCコレクタがポインタを辿る度にアドレス比較を行っているため、コストが心配である。2.の手法での実装を行う場合は、共有メモリセグメント上のセルが持つポインタを辿る際には、非GC中であっても、GC中と同じ方式で辿らせる (GCCAR,GCCDR
マクロを用いる)よう、実装を行う必要があると考えられる。
なお、共有メモリセグメント上のデータの内、SXML以外のデータ (全文・タグ・URL文字列など)に関しては、後述のVerno専用の Scheme関数がヒープ領域にコピーした上で、ユーザーへ渡す形での実装を行っている。したがって、GC(正確にはマーク)される恐れがあるのは、現在の所は SXMLデータのみとなる。
4.3 SCM上からの利用共有メモリセグメント上の SCMオブジェクトを、Scheme上で利用する際に発生する幾つかの問題点と、その解決のために行った実装を紹介する。
25

4.3.1 見えない
通常、SCM上で変数を定義した後、その変数名を入力すると変数の中身が出力される。しかしその変数にバインドされているデータが、共有メモリセグメント上の SXMLデータであった場合、処理系は unknown-heap表示を行う。
以下に例を示す:見えない¶ ³
> waseda#<unknown-heap 0x62823000>
µ ´しかし、unknown-heap表示にも関わらず、wasedaは関数の引数として与える事が可能である。
評価は出来る¶ ³
> (list? waseda)#t
> (length waseda)97001
> (caar waseda)#<unknown-heap 0x628e0750>
> (symbol? (caar waseda))#t
> (list? (caar waseda))#f
> (symbol->string (caar waseda))"*top*"
µ ´この現象の解決は容易であると考えられるが、
1. データの実体が共有メモリ空間上にある事が、視覚的に理解できる。
2. 97001ページ分の SXMLデータの中身を出力する等の、うっかりミスを防ぐ事が出来る。
というメリットもある。そこで、一般公開を行うまで、敢えてこのままにする事にした。
26

4.3.2 shm-copy
SXMLページに対して、加工や検索を行った結果を表示する際に、unknown-
heap表示だけでは結果が正しいのかを確認できない。そこで、共有メモリ領域上のオブジェクトをヒープ内にコピーするための関数 shm-copyと、共有メモリ領域に置いたままで中身を出力する関数 shm-printを実装した。
shm-copyと shm-print¶ ³
> (cadar waseda)#<unknown-heap 0x628e0760>
> (define obj (shm-copy (cadar waseda)))#<unspecified>
> obj(*pi* xml "version=\"1.0\"")
> (shm-print (caar waseda))*top*#<unknown-heap 0x628e0750> ;;コピーはしないので、返り値は見えない。
µ ´
4.3.3 equal? eq?関数
SXMLではタグ名がシンボル型で表現されているが、4.2.2において説明した通り、共有メモリセグメント上のシンボルは SCMのハッシュテーブル (symhash)
への登録を行っていない。そのため、2つのシンボルが同じ名前を持っていても、eq?および equal?関数が#fを返す現象が発生した。この問題は、大変にクリティカルであるので、R5RSに従い、SCMのソースの該当個所に以下を書き加えて対処した。
scl.c¶ ³
if(SYMBOLP(x)&&SYMBOLP(y)){//xと yが共に symbolであるなら
return st_equal(symbol2string(x),symbol2string(y));//(string=? x y)を返す。
};µ ´
27

equal?関数と symbol¶ ³
> (define symbol_shm (car (caddar waseda)))#<unspecified>
> (symbol? symbol_shm) ;;shm上のシンボル#t
> (symbol->string symbol_shm) ;;その名前"http://www.w3.org/1999/xhtml:html"
>(define symbol_new ;;同じ名前の’http://www.w3.org/1999/xhtml:html) ;;シンボルを定義
#<unspecified>
> (equal? ;;名前は同じであるのに(symbol->string symbol_new)(symbol->string symbol_shm))
#t
> (equal? symbol_new symbol_shm) ;;同じシンボルではない#f ;;とされる
µ ´
4.3.4 実装したScheme関数
実装したプリミティブ関数の一覧を示す。
28

関数 説明
(unigram-index-search str) 1-gramインデクスを用いて、文字列 strの検索を行う。URL型が並んだリストが返る。なるべく使わないほうが良い。
(url-num url) 文書 IDの値が、number型で返る。(url-pos url) 文書内での単語の位置が、number型で返る。(url-score url) 文書内での単語の出現回数が、number型で返る。(url-str url) URL文字列が、string型で返る。(url-digest-all url) タグを取り除いた文字列部が、string型で返る。(url-title url) titleタグに挟まれた文字列部が、string型で返る。(string->url url) 文字列から、URL型を得る。URL型又は#fが返る。(shm-sxml-init i) SXMLデータを展開するための、共有メモリ領域を
確保する。その上で、97001個の空リストを要素とするリストを作成する。
(shm-sxml-load sxmldata i) ヒープ上の SXMLデータを、shm-sxml-init関数で作成したリストへ、i番目の要素として格納する。SXMLデータは、ポインタ構造を保ったままコピーされる。
(shm-tag-write i) タグ名を保存するための、共有メモリ領域を確保する。(shm-tag-name i) タグ名を得る。(shm-copy obj) 共有メモリ領域上のオブジェクトをヒープ内にコピーし、返す。(shm-print obj) 無理矢理 printする。objが返る。
なお、objはCONS,STRING,MSYMBOLセルのみで構成されていると想定している。
(url-digest url n) 時間があれば。(url-link url)
(url-ilink url)
表 4.1: Scheme関数一覧
29

第5章 評価
本章では、実装を行ったソフトウェアの使用方法と使用例を紹介する。
5.1 データの主記憶への展開初めに下記のプログラムを用いて、共有メモリ上へのデータの展開を行う。
初期化プログラム¶ ³
(shm-tag-write 0);; タグ名 (シンボル) を置く場所を shm 上に確保。(shm-sxml-init 0);;SXML データ本体を置く場所を確保し、
;;97001 個の空要素を持つリストを作成。
(define (s n);;SXML ファイルを読み込む関数(read
(open-input-file
(string-append "/verno2/verno2/waseda/db/sxml/"
(number->string n) ".s"))
))
(define tmp ’())
(define loop
(lambda (n)
(do ((i 0 (+ i 1)) (y 0))
((= i n) i)
(set! tmp (s i)) ;;i ページ目の SXML データをファイルから読み、tmp に格納(shm-sxml-load tmp i) ;; 巨大リストの i 番目の要素として、tmp を shm 上にコピー。
)
))
(loop 97000)
;; この初期化作業は一度だけ行う。;;shm の状態確認には ipcs コマンド、データ消去には ipcrm コマンドを用いる。
µ ´
初期化作業を行った直後に、ipcsコマンドを実行した様子を示す。
ipcsコマンドの実行¶ ³
%ipcs -m
------ 共有メモリセグメント --------
キー shmid 所有者 権限 バイト nattch 状態0x6f01400f 589824 nagasawa 644 200000000 0
0x7401400f 622593 nagasawa 644 10000 0
0x6401400f 655362 nagasawa 644 352000000 0
0x7301400f 688131 nagasawa 644 1160000000 0
µ ´
30

5.2 文字列検索の使用例下の例では、従来のVernoでは不可能であった、日本語一文字の検索を行って
いる。文字列検索の使用例¶ ³
%telnet 8gb.verno 9999
Trying 133.9.215.91...
Connected to 8gb.verno.
Escape character is ’^]’.
(define results
(unigram-index-search "魏" 1)) ;; キーワード "魏" で検索する。#<unspecified>
(length results) ;; 結果はリストで返る。52 件ヒットした。52
results ;; 結果を表示。((114 449 1) (8256 95 6) (8992 54 1) (9053 54 1) (9473 59 1) (10109 55 1) (10169 55 1) (10
667 55 1) (10778 55 1) (16263 18291 1) (20800 11047 1) (23794 1779 1) (26243 2683 1) (3656
9 1923 1) (41476 14901 1) (47050 27306 3) (47348 8124 1) (47786 2039 1) (47932 1735 1) (51
947 3379 1) (55650 4416 1) (56492 2846 1) (58715 15178 1) (58736 6291 1) (59226 3379 1) (6
1212 476 1) (61316 873 1) (61456 224 1) (61552 873 1) (61623 3379 1) (61667 873 1) (62950
2846 1) (64186 1237 1) (64210 325 3) (64372 3331 1) (64886 2088 1) (64894 545 1) (65379 12
73 1) (65541 2846 1) (66104 476 1) (67387 24 1) (67398 2670 1) (68100 4406 1) (68417 4078
1) (70371 1940 1) (74070 11047 1) (80233 1938 1) (80391 1779 1) (85605 594 1) (88380 1572
1) (93901 571 1) (94885 3480 1))
(list? (car results)) ;; 各検索結果もまた、リストで表現される。#t
(number? (caar results)) ;;114 は、検索結果 1 件目のページ番号であり、#t ;;number 型で、表されている。
(number? (cadar results)) ;; 同様に 449 は、ページ内での出現位置を表す。#t
(number? (caddar results)) ;;1 は、114 番のページに、"魏"が 1 回出現した#t ;; 事を表している。
(url-str (car results)) ;; 検索結果の 1 件目の"www.ueda.info.waseda.ac.jp/student_j.html" ;;URL 文字列を表示。(url-title (car results)) ;; 検索結果の 1 件目のUeda Lab. Students ;; タイトルを表示。
(url-str (cadr results))
"database.littera.waseda.ac.jp/aizu/tenji/qtlist.html"
(url-title (cadr results))
qtlist
(url-str (caddr results))
"database.littera.waseda.ac.jp/aizu/tenji/qt-4.html"
(url-title (cadr results))
qtlist
(exit)
Connection closed by foreign host.
µ ´従来の verno-elk/verno-scm上で動作していたプログラムは、文字列検索関数を修正する事で、ほぼ全て使用可能となる。
31

5.3 SXMLデータの使用例SXPathを用いた検索を行う例を示す。
SXPathを用いた検索¶ ³
µ ´従来のVernoでは難しいとされていた、構造に対する検索が実現している。
32

5.4 破壊的代入変数 waseda にバインドされた共有メモリセグメント上の SXML データは、
ReadOnlyでAttachされている。そのため、set-car!や set-cdr!等の関数を用いて、SXMLデータを直接書き換えようとすると、関数が不正終了する。
破壊的代入を試みる¶ ³%telnet 8gb.verno 9999
Trying 133.9.215.91...
Connected to 8gb.verno.
Escape character is ’^]’.
(list? waseda) ;;waseda は SXML データが格納されたリストである。#t
(length waseda)
97001
(set-car! waseda "anything") ;;set-car!や set-cdr!による、破壊的代入は出来ない。ERROR: segment violation 11
; in top level environment.
(list? (car waseda)) ;; リストは元のままである。#t
(define waseda "anything") ;;(set! waseda "anything") などの関数で、#<unspecified> ;;waseda を別のデータへバインドする事は可能であり、
waseda
"anything"
(string? waseda) ;; ここでは文字列"anything"に置き換わっているが、#t
(gc) ;;Garbage Collection が起きた時点で#<unspecified> ;;(ここでは意図的に実行している)
(string? waseda)
#f
(list? waseda) ;; 元に戻る仕様となっている。#t
(length waseda)
97001
(exit)
Connection closed by foreign host.
µ ´ユーザーが誤って、共有メモリセグメント上のデータを消す事が無いように配慮した仕様である。
33

5.5 応用例
5.5.1 画像の一覧を作成する
5.3では SXPathを用いて aタグの抽出を行う例を示したが、その応用例として上田研究室ドメインのWebページ内で用いられている画像を抽出する例を示す。(付録A.1)
クエリーは具体的には次の処理を行っている:
各ページに対して 1. 上田研究室ドメインのページであるかを判定し、そうであるなら 2以降を 実行する。 2. SXPathを用い、imgタグの src属性値を抽出。 3. ファイル名が相対パスで書かれていれば、絶対パスに直す。 4. 画像の重複出現を防ぐため、ファイル名順でリストに格納する。 5. HTML形式で出力する。
3と 4の処理を Schemeの関数で柔軟に記述出来る点が、Vernoならではの特徴であると言える。結果は、図 5.1のように表示された。
図 5.1: 結果をWWWブラウザで表示
34

5.5.2 表を加工する
次に、SXMLデータの加工例として、上田研究室・学生一覧のページを、Web
ページの充実度の順にソートして出力する例を示す。(付録A.2)
クエリーは具体的には次の処理を行っている:
1. SXMLデータから、リンクが張られているメンバーを抽出する。 2. その中で、リンクが存在しているものだけを残す。 3. Webページの充実度を算出する。 4. ソートして、出力する。
なお、ここでは各自のページの内、収集されたページ内のタグ部を除く総文字列の長さを充実度として計算している。
35

第6章 考察
本章では、第 5章での検索例を通しての、主記憶言語の有用性・処理速度・主記憶の使用量について考察を行う。
6.1 有用性初めに、SXMLデータのシステムへの組み込みが成功した事について述べる。
従来、SXMLデータは、Vernoのデータとして用意されていなかったが、主記憶言語の利用によって、ユーザーが自由に使える形で、SXMLデータの提供が可能となった。
従来のVernoでは、各データをデータベースに保存し、そのデータを専用のAPI
関数を用い、Schemeの型に変換した上で、検索言語上で利用していた。これに対して本研究では、SXMLデータを主記憶上に保存し、Schemeのデータとして直接参照できるよう、実装を行った。これにより、ユーザーが直感的にVernoのデータを利用可能となった。ユーザーは変数名wasedaさえ知っていれば、Verno
のデータを用いた Schemeプログラムを書く事が可能となった。
SXMLデータ以外のデータに関しては、従来の検索言語と同様、Verno専用のScheme関数を用いなければならない。しかし、その多くのデータは、SXMLデータから直接抽出する事が可能であるとも言える。
SXMLデータの提供による利点としては、何よりSXPathの利用が可能となった事が挙げられる。SXMLデータに対する SXPathの利用は、Vernoにおけるページ構造に対する検索の 1つの手段である。従来Verno班では、あらかじめ専用のデータを用意し、独自に検索のための関数を実装する形で、ページ構造に対する検索の実現が試みられてきた。これに対して、SXPathは、コンパクトな Scheme
コードのみで完結しているにも関わらず、従来のVernoで示されていた検索例よりもはるかに複雑な検索や操作を、より短いコードで記述する事が出来る。主に速度に関して、SXPathを本格的に利用するための課題は多いが、処理速度が遅くともより複雑な検索が可能となった事に、意義はあると考える。
36

またSXMLデータの使い道として、SXPathを用いた利用の他に、分散Scheme処理系の研究における利用が考えられる。これは、排他的なVernoのデータを持った Scheme処理系同士が、検索結果の受け渡しを行う際に SXMLデータを用いるという案であり、Verno班で研究が行われている。[1be]
次に、ほぼ全てのデータを共有メモリセグメント上に展開したことの意味について述べる。従来のVernoの検索言語は、起動時にディスク上のデータの主記憶上へのマッピングを試みるため、クエリーを受け付けてから大量のディスクアクセスが発生するという問題を抱えていた。また、検索言語は Inetdによって複数が同時に起動され得るが、データがプライベートにマップされるため、大量のクエリーを同時に受けた際の主記憶の使用量が問題となっていた。
これに対して主記憶検索言語は、起動時に共有メモリセグメントの attachを行うのみであるため、少なくともディスクアクセスは発生しない。恐らく、RAM
ディスクやmfsを併用すれば、完全にディスクアクセスを無くす事も可能になるだろう。また、共有メモリを用いたため、主記憶上でのデータの重複も防がれている。結論として、本研究のアプローチを用いれば Inetdを利用した方法であっても、簡易検索言語 fhandleの代わりに Scheme処理系を置く事が可能なのではないかと、考えている。
6.2 処理速度ここでは、主記憶検索言語の処理速度について考察を行う。
初めに、文字列検索に対する検索について述べる。本研究では、文字列が長くなると、今の実装では unigram-search-index関数は使えない。
segalou、日本語 6文字以内なら 0.02秒以下で検索出来る1-6Gramインデクスが存在している。データ貼る?
37

にもかかわらず、下手をすると分単位のオーダーの実装。
圧縮を行った上で、6Gramくらいまでは、そのまま載せるべきである。
suffix-Arrayに期待。suffix-Arrayとのコラボレーションの図。
SXPathについて
大量のデータでもGC処理は行ってない。比較する事が既に間違っているが、XMLデータベースとは、まったく比較にならないくらい遅い。
実は自分で書いた方が速い事もある。
(define query1 (sxpath ’(// http://www.w3.org/1999/xhtml:title)))
(define results(shm-loop query1))
(define extract
(lambda (input answer tagname)
(cond
((null? input) answer)
((list? (car input)) (extract (cdr input)
(extract (car input) answer tagname) tagname))
((equal? (car input) tagname) (cons (cdr input) answer))
(else (extract (cdr input) answer tagname)))))
(define (query2 target)(extract target ’() ’http://www.w3.org/1999/xhtml:title))
(define results2 (shm-loop query2))
SXPathクエリーを高速に実行するためには、(主記憶版タグデータベース)タグのインデクスが必要。絵。
38

作るのは、さほど難しくないが、これも主記憶の量が問題となる。http://www.w3で始まる由緒あるタグのみインデクシングするとか。そのインデクスが出来て、sxpathのなかで利用するようにすれば高速にはなるだろうけど、そうまでして、”ちょっと遅くて、Schemeプログラムも動く、XMLデータベースもどき”。を作る必要があるか?
6.3 主記憶の使用量に関して1プロセス 2GBの制限が非常に重要。
\\
Larbin All 874434560(内 6914123が Index)
XML files: 97926 segalou:/tmp/eraseme 922308608
SXML files: 1217609728
03:08 [kakky] テキスト+テキスト x約 3+テキスト x約 0.8
03:09 [ngswdsk] 163 + 163*3 + 163*0.8か03:09 [ngswdsk] 800-900MBか。
SXMLデータの、比率のグラフをここに貼る。それと、SXMLデータの digと、そうじゃない digの比率を棒グラフで。この膨大な大きさのデータが、1つの変数にバインドされている事から、膨大な大きさの結果を返すプログラムが簡単に書けてしまう。
SXPathについてとかく、結果のリストが膨大な大きさになる事に注意が必要従来は、かなり範囲を絞らなければならなかったけど、やっぱり絞ってからの利用か。今のところは、ループの中で各ページの結果をその都度出力する、とかを推奨
39

(query waseda)出来ないのは、関数 queryが末尾再帰で無いから?wasedaの各要素に対して queryを実行し、リストにして返す事は出来る。
unigramインデクスを退避させたこと。
64bitで全て解決?
40

第7章 まとめと今後の課題
7.1 まとめSchemeならではのデータとして、SXMLデータが提供される。ユーザーが直感的にVernoのデータを利用出来る。Scheme処理系を用いたCGIサービスへ一歩近づいた。2GBの壁が問題である。
7.2 今後の課題使ってもらう事が大事。今後、学内版・主記憶版Vernoをサービスとして公開
するならば、第??章で述べた通り、32bit機なら n-Gramか suffix-arrayを持った別プロセスのデータをどうにかもってくる、64bit機なら n-Gramか suffix-array
を attachさせる。
2GBの壁超えられるなら、64bit機が欲しい。
41

謝辞
本研究を進めるにあたって、全般に渡りご指導頂いた指導教官の上田和紀教授に深く感謝いたします。また、これまでVernoに携わられ土台を築いて下さったVerno班の先輩方と、研究の上で多くの意見を頂いた上田研究室の皆様に感謝致します。最後に、研究で用いたソフトウェアの開発に携わる人々、とりわけ SXML関連の論文とツールを数多く発表されているOleg Kiselyov氏、SCMの開発をされているAubrey Jaffer氏に、心より感謝致します。
42

参考文献
[1] Oleg Kiselyov : A better XML parser through functional programming 2002.
[2] Oleg Kiselyov : SXML Specification ACM SIGPLAN Notices, v.37(6), pp.
52-58, June 2002.
[3] Oleg Kiselyov, Kirill Lisovsky: XML, XPath, XSLT implementations as
SXML, SXPath, and SXSLT 2002.
[4] SCM : http://swissnet.ai.mit.edu/~jaffer/SCM.html
[5] Revised4 Report on Scheme : W. Clinger and J. Rees (eds.), Revised4 Report
on the Algorithmic Language Scheme, ACM Lisp Pointers, Vol. 4, No. 3,
pp. 1–55, 1991.
[6] Revised5 Report on Scheme : R. Kelsey, W. Clinger, and J. Rees (eds.),
Revised5 Report on the Algorithmic Language Scheme. Higher-Order and
Symbolic Computation, Vol. 11, No. 1, pp. 7–105, 1998.
[7] IEEE Computer Society, IEEE Standard for the Scheme Programming Lan-
guage, IEEE Std 1178-1990, New York, 1991.
[8] Verno : http://verno.ueda.info.waseda.ac.jp/
[9] verno-elk : http://verno.ueda.info.waseda.ac.jp/network/scheme.html
[10] 金子宗太郎 : WWW全文検索システムVernoにおけるタグデータベースの設計と実装,早稲田大学理工学部情報学科 2000年度卒業論文,2001.
[11] 沼尻務 : 日本語全文検索エンジンVernoにおけるインデックスデータベースの実装と評価,早稲田大学理工学部 1997年度卒業論文,1998.
[12] 渡辺高志,田川信一,沼尻務,竹岡厚,上田和紀 : WWW全文検索システムVernoのアーキテクチャ,情報処理学会第 58回全国大会講演論文集,4T-07,1999.
[13] 渡辺高志 : 日本語全文検索エンジンVernoにおける検索言語の設計と実装,早稲田大学大学院理工学研究科情報科学専攻 1999年度修士論文,2000.
43

付 録A 付録
A.1 sample1.scm
A.2 sample2.scm
44